
Как правило, большие компании работают с широким ассортиментом продуктов. Чтобы им управлять, используются системы учёта. Они помогают отслеживать продукт на всех этапах жизненного цикла — от производства до продажи.
Неотъемлемая часть управления продуктами — это анализ конкурентов. Он помогает понять, какие функции и возможности есть на рынке, какие из них популярны и востребованы пользователями. Одна из главных проблем этого процесса — анализировать конкурентов приходится вручную. Это занимает много времени и сил, которые можно использовать более эффективно.
В этом уроке вы узнаете, как происходит решение задачи с использованием нейронных сетей, поговорим об этапах нейросетевого моделирования, рассмотрим решение задачи в общем виде.
Для того, чтобы решить какую-то задачу при помощи нейронной сети, эту сеть необходимо предварительно обучить. Как мы уже говорили (см. урок 2.3) существуют несколько способов обучения искусственных нейронных сетей:
- с учителем
- без учителя
- с подкреплением.
Говоря по-простому, нейронная сеть — это черный ящик. Вы подаете на вход, какие-либо значения, и получаете от нее ответ на выходе.
Нейронная сеть строит сложную функциональную зависимость выхода от входа.
Чтобы нейронная сеть построила эту зависимость правильно, пройдите 9 шагов. Эти шаги часто называют этапами нейросетевого моделирования.
Существует много разновидностей, решений и конструктивных элементов рекуррентных нейронных сетей.
Трудность рекуррентной сети заключается в том, что если учитывать каждый шаг времени, то становится необходимым для каждого шага времени создавать свой слой нейронов, что вызывает серьёзные вычислительные сложности. Кроме того, многослойные реализации оказываются вычислительно неустойчивыми, так как в них, как правило, исчезают или зашкаливают веса. Если ограничить расчёт фиксированным временным окном, то полученные модели не будут отражать долгосрочных трендов. Различные подходы пытаются усовершенствовать модель исторической памяти и механизм запоминания и забывания.
Эта базовая архитектура разработана в 1980-х. Сеть строится из узлов, каждый из которых соединён со всеми другими узлами. У каждого нейрона порог активации меняется со временем и является вещественным числом. Каждое соединение имеет переменный вещественный вес. Узлы разделяются на входные, выходные и скрытые.
Для обучения с учителем с дискретным временем, каждый (дискретный) шаг времени на входные узлы подаются данные, прочие узлы завершают свою активацию, а выходные сигналы готовятся для передачи нейроном следующего уровня. Если, например, сеть отвечает за распознавание речи, в результате на выходные узлы поступают уже метки (распознанные слова).
В обучении с подкреплением (reinforcement learning) нет учителя, обеспечивающего целевые сигналы для сети, вместо этого иногда используется функция приспособленности (годности) или функция оценки (reward function), по которой проводится оценка качества работы сети, при этом значения на выходе оказывает влияние на поведение сети на входе. В частности, если сеть реализует игру, на выходе измеряется количество пунктов выигрыша или оценки позиции.
Каждая цепочка вычисляет ошибку как суммарную девиацию по выходным сигналам сети. Если имеется набор образцов обучения, ошибка вычисляется с учётом ошибок каждого отдельного образца.
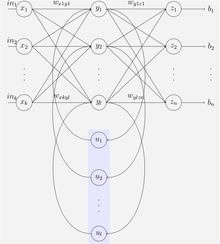
Сети Элмана и Джордана называют также «простыми рекуррентными сетями» (SRN).
- Сеть Элмана[25]
- Сеть Джордана[26]


Обозначения переменных и функций:
- Recurrent Neural Networks Tutorial
- Jordan, M. I. Serial order: A parallel distributed processing approach // Institute for Cognitive Science Report 8604. — University of California, San Diego, 1986.
- Elman, J.L. Finding structure in time // Cognitive Science. — 1990. — . (недоступная ссылка)
- Роль математики в нейросетевых алгоритмах
- Написание простого кода
- Анализ отличий нейросетевых алгоритмов
- Автоматизация сбора информации о конкурентах
- Пример решения задачи прогноза погоды в Москве при помощи нейронной сети
- 1. Постановка задачи
- 2. Выбор источников обучающей выборки
- 3. Выбор архитектуры нейронной сети
- 4. Определение структуры нейронной сети
- 5. Подготовка обучающей выборки
- 6. Выбор алгоритма обучения
- 7. Проведение обучения нейросетевой модели
- 8. Оценка адекватности работы модели
- 9. Применение нейросетевой модели на практике
- Преимущества применения нейросетей в бизнес-аналитике
- Небольшое домашнее задание
- Обзор существующих видов нейросетевых алгоритмов
- Минимизация рисков и помощь в принятии решения
- Расшифровка видеовстреч, генерация отчётов
- Преимущества GigaChat
- Недостатки нейросетей для бизнес-аналитики
- Автоматизация рутинных задач
- Нейросетевые алгоритмы и их виды. Анализ существующих нейросетевых алгоритмов. Роль математики
- Библиотеки для нейросетевых алгоритмов
- Этапы нейросетевого моделирования
- RAG, или при чём тут GigaChat
- Нейросети в бизнес-аналитике
- Создание новых идей удержания клиентов
- Что получилось в итоге
- Заключение
- Выводы
Роль математики в нейросетевых алгоритмах
В рамках исследования рассматривалась роль математики в нейросетевых алгоритмах и то, какие математические концепции применяются в их разработке и обучении:
- Линейная алгебра
- Оптимизация
- Теория вероятностей и статистика
- Дифференциальное исчисление
- Математические функции и активации
- Вероятностные графические модели
Линейная алгебра является фундаментальной математической дисциплиной, которая широко применяется в нейросетевых алгоритмах. Матрицы и векторы используются для представления данных и параметров модели, а операции над ними, такие как умножение матриц, позволяют проводить вычисления в сети.
Оптимизация является ключевой задачей в обучении нейросетевых алгоритмов. Она заключается в нахождении оптимальных значений параметров модели, чтобы минимизировать ошибку или функцию потерь. Математические методы оптимизации, такие как градиентный спуск, используются для обновления параметров модели на основе градиента функции потерь.
Теория вероятностей и статистика играют важную роль в нейросетевых алгоритмах. Они позволяют моделировать и оценивать вероятности различных событий и их влияние на модель. Байесовские методы и статистические тесты могут использоваться для принятия решений на основе данных и оценки уверенности модели.
Дифференциальное исчисление является основой обучения нейросетевых алгоритмов. Градиенты функции потерь по параметрам модели вычисляются с помощью дифференцирования, что позволяет обновлять параметры модели в процессе обучения. Алгоритм обратного распространения ошибки основан на применении цепного правила дифференцирования.
Математические функции, такие как сигмоида, гиперболический тангенс, ReLU (Rectified Linear Unit) и другие, используются в нейросетевых алгоритмах в качестве активационных функций. Они вносят нелинейность в модель и позволяют ей моделировать сложные зависимости между данными.
Вероятностные графические модели представляют собой математические модели, которые объединяют вероятностные и графовые концепции. Они используются в некоторых типах нейросетевых алгоритмов, таких как генеративные модели и модели с учителем. Вероятностные графические модели позволяют моделировать сложные зависимости между переменными и решать задачи инференции и генерации данных.
Написание простого кода
Аналитику нужны знания архитектуры информационных систем и требований к интеграции.
Часто для работы БА необходимо:
- тестировать API с помощью Postman или аналогичных сервисов;
- составлять запросы REST API, SOAP и GraphQL;
- писать простые скрипты получения данных из PostgreSQL и генерации отчётов по заданным параметрам.
GigaChat может писать на Javascript, Java, Python и других языках программирования. Также нейросеть можно попросить найти ошибки в исходном коде, предоставленном пользователем. Чтобы получить результат, необходимо правильно составить промпты.
Анализ отличий нейросетевых алгоритмов
Аназил отличий нейросетевых алгоритмов позволил лучше понять и оценить их уникальные особенности, преимущества и ограничения. При этом, были выделены несколько ключевых аспектов:
- Архитектура нейросети
- Обучение и оптимизация
- Функции активации
- Размер данных и обработка
- Проблема переобучения
- Скорость и эффективность
- Применение и области применения
Различные алгоритмы обучения, такие как обратное распространение ошибки (backpropagation), стохастический градиентный спуск (SGD) и алгоритмы оптимизации, могут быть использованы для настройки параметров нейросети и достижения лучших результатов.
Выбор подходящей функции активации, такой как сигмоида, гиперболический тангенс, ReLU (Rectified Linear Unit) и другие, может значительно влиять на производительность и способность нейросети обучаться.
Различные алгоритмы могут иметь разные требования к объему и типу данных, а также к предварительной обработке данных, включая масштабирование, нормализацию, сглаживание и т. д.
Нейросетевые алгоритмы могут иметь тенденцию к переобучению, особенно при работе с небольшими наборами данных. Поэтому различные методы регуляризации, такие как dropout, L1 и L2 регуляризация, могут использоваться для борьбы с переобучением.
Различные нейросетевые алгоритмы могут быть более подходящими для конкретных задач и областей, таких как обработка естественного языка (NLP), компьютерное зрение, анализ временных рядов и другие.
Автоматизация сбора информации о конкурентах
Иногда при автоматизации процессов возникают проблемы, связанные с получением данных и извлечением информации из них. В результате исследования мы столкнулись со следующими вопросами:
Как находить конкурентов продукта и информацию о них?
Как находить и формировать поле для карточки конкурента — документа, который содержит данные о конкурентах: название компании, логотип, контактную информацию, адрес сайта, описание продуктов или услуг, целевую аудиторию, ценовую политику?
Первый вопрос решается просто. Делаем запрос в поисковой движок по интересующему продукту и собираем тексты с нужного количества ссылок. Этот процесс сбора данных из интернета называется парсингом.
Для генерации поля карточки конкурента кажется логичным использовать LLM. Мы взяли GigaChat — нейросетевую модель Сбера. Но среди собранных из интернета данных попадается много мусора, который затрудняет анализ и извлечение нужной информации. А нам хотелось бы использовать только информативные тексты. Такие тексты отбираются с помощью retrieval — способа получения релевантных документов по определенному запросу. А метод генерации информации по отобранным документам с использованием LLM называется retrieval‑augmented generation (RAG).
Таким образом, наш алгоритм сбора информации о конкурентах выглядит так:
собираем информацию о внутреннем продукте из локальной системы продуктового учета;
формируем запрос в Google для поиска конкурентов;
парсим результаты поисковой выдачи;
достаем имена конкурентов, используя RAG;
собираем карточку каждого конкурента подобным образом (шаги 2-4).
Пример решения задачи прогноза погоды в Москве при помощи нейронной сети
1. Постановка задачи
Предположим, вы хотите решить задачу прогнозирования метеоусловий. Для простоты возьмем только один параметр — температуру воздуха.
На этом этапе обязательно нужно определиться какой параметр мы будете предсказывать. Температура воздуха может быть среднегодовая, среднемесячная, среднесуточная. Исходя из этого допущения, нужно будет определять источник данных для обучающей выборки.
В при постановке задачи определяем, что требуется решить задачу прогнозирования, которая сводится к построению аппроксимирующей зависимости выходного значения от входного. То есть на вход вы будете подавать значение температуры сегодня, чтобы получить значение температуры завтра (прогноз).
2. Выбор источников обучающей выборки
В качестве источника данных можно использовать достоверные данные из любого агрегатора погоды (Яндекс.Погода, Gismeteo и др.).
3. Выбор архитектуры нейронной сети
С решением задачи нелинейной аппроксимации хорошо справляются нейронные сети прямого распространения. Выбираем эту архитектуру.
4. Определение структуры нейронной сети
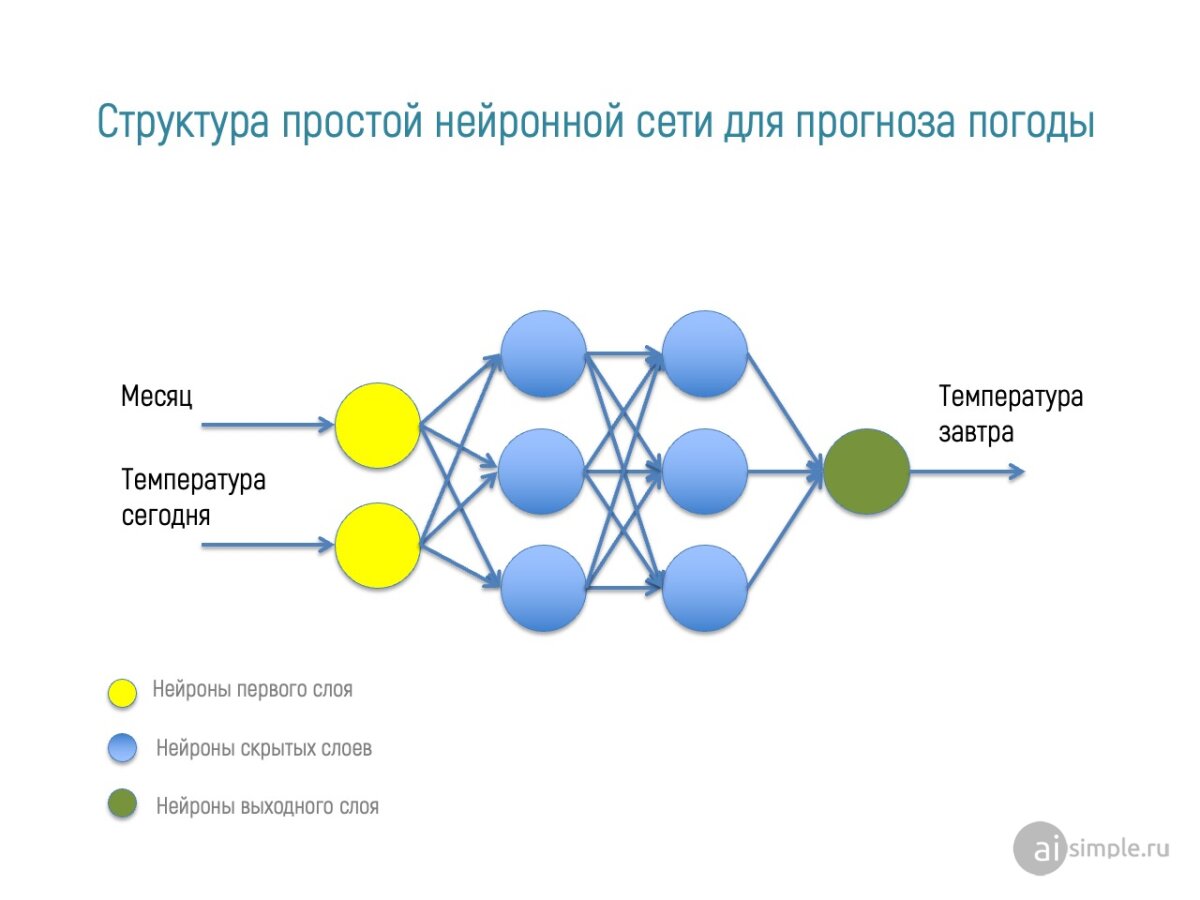
На вход нейронной сети рекомендуем подавать два значения. Месяц от 1 до 12 и значение температуры. Сеть будет содержать два нейрона первого слоя. Определим число скрытых слоев, например 2 слоя по 3 нейрона в каждом. И один нейрон выходного слоя. Получится структура изображенная на картинке ниже.
5. Подготовка обучающей выборки
У вас есть выборка примеров для обучения — значения температуры воздуха в Москве в разбивке по месяцам и по дням за 10 лет. То есть 365*10 = 3650 строк. Эти цифры нужно нормировать в диапазоне от -1 до 1 (см. статью Способы нормализации данных).
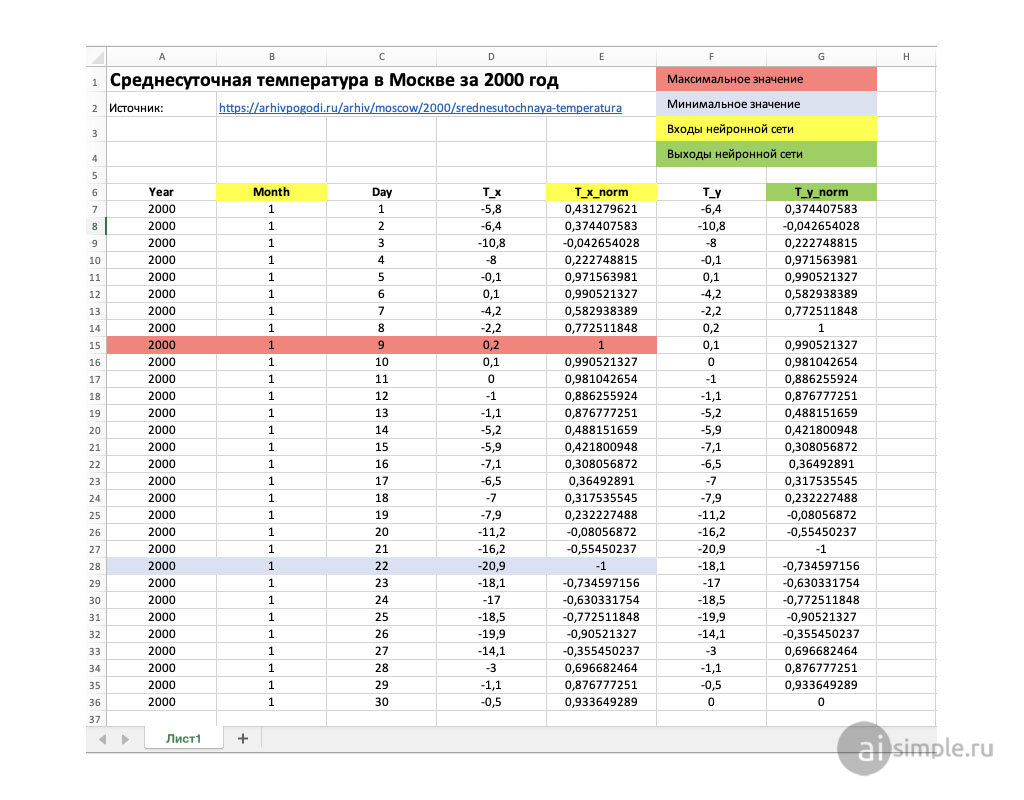
Стоит подумать над исключением аномальных значений, например +1-2 градус в в июне, или +5-10 градусов в январе, так как это экстремальные значения. Если их не исключать сеть может давать худший прогноз, т. к. будет учитывать эти аномалии, встречающиеся раз в несколько десятилетий.
Выборка должна быть разделена на обучающую и тестовую. Обучающую выборку используем для обучения, тестовую для проверку адекватности модели.
6. Выбор алгоритма обучения
В качестве алгоритма обучения НС можно выбрать метод обратного распространения ошибки (см. урок 2.4.) или любой градиентный метод.
7. Проведение обучения нейросетевой модели
Проводим обучение нейронной сети при помощи Python или любого другого пакета прикладных программ. Обучение ведем до достижения заданной ошибки или числа эпох.
8. Оценка адекватности работы модели
Оценку адекватности проводим на тестовых данных. Например, можно рассчитать среднеквадратичную ошибку для 10-20 примеров, если она будет выше 80-90%, то модель можно использовать для прогноза. Если нет — тогда есть три варианта:
— сеть необходимо дообучить, добавив в обучающую выборку новые примеры,
— использовать другие алгоритмы обучения (оптимизаторы в Python),
— изменить структуру сети (число скрытых слоев и/или количество нейронов в них),
9. Применение нейросетевой модели на практике
Теперь нейронную сеть можно использовать «в боевых условиях», подав текущий месяц и текущую температуру воздуха в Москве и посмотреть в реальности насколько ваша модель точно предсказывает погоду.
Преимущества применения нейросетей в бизнес-аналитике
Искусственный интеллект не заменит аналитика, но сэкономит время, сможет обработать больше данных и вывести закономерности, подсветить слабые места в бизнес-процессах.
Внедрение ИИ в аналитике помогает автоматизировать рутинные задачи бизнеса:
- перевести с русского на английский и наоборот с учётом стилистики и контекста;
- автоматизировать ручные процессы для извлечения данных;
- оптимизировать ресурсы на составление отчётов, дашбордов;
- найти скрытые тенденции и взаимосвязи;
- перевести данные из одного формата в другой (к примеру, аудиозаписи техподдержки в текст);
- выявить недобросовестные практики при выполнении бизнес-процесса;
- спрогнозировать и предупредить потенциальные сбои.
Примерами использования технологий искусственного интеллекта в аналитике могут быть:
Для работы с данными (в том числе и BigData) используются платформы вроде SberData Platform. SDP предоставляет аналитикам возможности для:
- обработки Big Data;
- визуализации;
- разработки ML-моделей.
Небольшое домашнее задание
В качестве задачи на подумать, можете самостоятельно концептуально решить вот эту задачу.
- Предложите по каким параметрам можно оценить клиентов, просматривая их трафик?
- Какую модель(-ли) нейронной сети можно использовать для данной задачи? Нарисуйте схему.
- Какое количество нейронов необходимо во входном и выходном слое? Почему?
Ответ под спойлером:
Обзор существующих видов нейросетевых алгоритмов
- Искусственные нейронные сети (ИНС)
- Сверточные нейронные сети (СНС)
- Рекуррентные нейронные сети (РНС)
- Генеративные нейронные сети (ГНС)
- Многоагентные системы
ИНС являются наиболее распространенным видом нейросетевых алгоритмов. Они состоят из множества искусственных нейронов, которые моделируют работу биологических нейронов. ИНС имеют различные архитектуры, такие как однослойные перцептроны, многослойные перцептроны и рекуррентные нейронные сети. Они применяются для задач классификации, регрессии, обработки естественного языка и других.
СНС специализируются на обработке визуальных данных, таких как изображения и видео. Они имеют особую архитектуру, включающую сверточные слои, пулинговые слои и полносвязные слои. СНС способны автоматически извлекать визуальные признаки из входных данных и применяются в задачах компьютерного зрения, распознавания образов, сегментации изображений и др.
РНС предназначены для работы с последовательными данными, где имеется зависимость между текущим состоянием и предыдущими состояниями. Они имеют обратные связи между нейронами, что позволяет им сохранять информацию о предыдущих входах. РНС широко применяются в задачах обработки естественного языка, машинного перевода, анализа временных рядов и других.
ГНС позволяют генерировать новые данные, имитируя статистические характеристики обучающего набора данных. Они могут быть использованы для генерации изображений, текстов, звуков и других типов данных. Примерами генеративных моделей являются автокодировщики, генеративно-состязательные сети (GAN) и вариационные автокодировщики (VAE).
Многоагентные системы представляют собой сеть нейросетей, работающих в сотрудничестве для решения сложных задач. Каждый агент представляет собой отдельную нейросеть, которая может иметь свои особенности и цели. Многоагентные системы могут использоваться для решения задач координации, распределенного обучения и управления.
Минимизация рисков и помощь в принятии решения
Частая задача BA — описать текущие бизнес-процессы от начала и до конца.
Для представления бизнес-процессов используют нотации BPMN (Business Process Model and Notation), DMN (Decision Model and Notation), CMMN (Case Management Model and Notation) или другие.
GigaChat можно попросить описать или искусственно смоделировать бизнес-процесс. На основе идей, предложенных нейросетевым разумом, разрабатывают возможные сценарии развития ситуации и принимают решения.
Аналитиков часто приглашают, когда у крупного бизнеса много рутинных процессов. Чтобы не разбирать каждый вручную, можно использовать системы интеллектуального анализа — к примеру, Sber Process Mining.
Как работает платформа:
- строит граф процесса (абстрактную модель);
- рассчитывает ключевые метрики;
- анализирует длительность операций, соответствие нормативам, SLA (Service Level Agreement);
- находит повторы, обнаруживает узкие места;
- формирует оптимальный сценарий выполнения бизнес‑процесса.
Автоматическое исследование бизнес-процессов компании на основе искусственного интеллекта позволяет:
- выявить кейсы неэффективности (высокая длительность этапа, зацикленность, Bottle neck и прочие);
- провести бенчмаркинг по значимым метрикам (регион, клиентский сегмент, канал продаж и другие);
- построить идеальную структуру процесса, предсказать метрики и структуру.
AI (artificial intelligence) в SberProcessMining позволяет проанализировать бизнес-процессы и усовершенствовать их.
Расшифровка видеовстреч, генерация отчётов
Работа бизнес-аналитика на проекте, как правило, подразумевает частые видеовстречи с командой и заказчиком. Это могут быть:
- тестировщики;
- разработчики;
- дизайнеры;
- продакт-менеджеры;
- технические писатели;
- руководители подразделений и другие.
Целями созвонов могут быть:
- демонстрация продукта (демо);
- ежедневные командные встречи (Daily Meeting, Standup Meeting);
- сбор информации для формирования бэклога на развитие продукта;
- обзор предоставления услуг (Service Delivery Review);
- анализ рисков (Risk Review) и другие.

Преимущества GigaChat
GigaChat — нейросетевая модель, обученная на 300 Гб данных. Искусственный интеллект понимает русский и английский языки. ИИ постоянно совершенствуется (в том числе и на основе пользовательских оценок). Сервис доступен бизнесу и частным лицам.
Основные особенности GigaChat для бизнес-анализа:
- модальность — ИИ может писать тексты и код, а также генерировать изображения;
- набор промптов — примеры подсказок искусственному интеллекту доступны в каталоге;
- простота интеграции и использования — подключение по API GigaChat, наличие GigaChain SDK;
- работа в условиях нагрузок — GigaChat поддерживает высокую интенсивность взаимодействия.
ИИ GigaChat можно использовать в ежедневной работе аналитика. Сервис может помочь в подготовке макетов UI/UX, обучении и наставничестве коллег, управлении бэклогом, создании пользовательских историй, моделировании данных, подготовке презентаций и демо для бизнеса, проведении дискавери-фазы и бенчмаркинга. Применение AI (artificial intelligence) не заменит живого специалиста, но сэкономит время и избавит от рутины.
Недостатки нейросетей для бизнес-аналитики
Искусственный интеллект помогает автоматизировать часть процессов, но не заменяет специалиста с опытом. К примеру, ИИ не сможет пообщаться с бизнесом, понять требования и возможность реализации, обработать и формализовать, перевести на язык разработчиков, проконтролировать результат.
Чтобы нейросеть генерировала результат, аналитику необходимо направлять её при помощи промптов. От качества и точности задания зависит результат, который выдаст ИИ.
Автоматизация рутинных задач
SaluteRPA (Robotic Process Automation) позволяют автоматизировать часть ежедневной работы аналитика:
- конвертировать изображения в текст;
- искать фразы, абзацы, строки;
- обнаруживать таблицы.
Роботы умеют извлекать набор данных, необходимых для дальнейшей работы специалиста.
Встроенная нейросетевая модель GigaChat позволяет быстро создавать и настраивать сценарии автоматизации.

Кроме этого, искусственный интеллект GigaChat можно использовать и для других рутинных задач аналитика. Это, например:
- выжимки из обсуждения (краткое содержание);
- создание баз знаний, чат-ботов для обучения младших коллег и адаптации новых сотрудников;
- планирование рабочего процесса (включая выделение, декомпозицию и приоритизацию задач);
- управление бэклогом (product backlog) с быстрым поиском по заданным параметрам;
- генерация структуры презентаций (в том числе и демо продукта);
- перевод с/на английский;
- проектирование систем, логики уровня данных, бизнес-процессов;
- предоставление информации по запросу пользователя (например, как составить сценарий приёмочного тестирования или пользовательский мануал) и многое другое.
Искусственный интеллект GigaChat может работать с контекстом разной структуры (например, можно передавать историю взаимодействия).
Нейросетевые алгоритмы и их виды. Анализ существующих нейросетевых алгоритмов. Роль математики
Доронина Анна Владимировна – студент факультета Информационных систем и технологий Поволжского государственного университета телекоммуникаций и информатики.
Захарова Оксана Игоревна – заместитель заведующего факультета Информационных систем и технологий Научно-исследовательской лаборатории искусственного интеллекта Поволжского государственного университета телекоммуникаций и информатики.
Аннотация: Данная статья представляет обзор нейросетевых алгоритмов и их различных видов. Рассматривается роль математики в нейросетевых алгоритмах и важность ее понимания для эффективного применения этих алгоритмов. Также освещаются различные библиотеки, используемые для разработки нейросетевых моделей. Отличия существующих алгоритмов также анализируются с целью понимания и выбора наиболее подходящего алгоритма для конкретной задачи. Эта статья предоставляет общий обзор нейросетевых алгоритмов и может служить введением для тех, кто интересуется искусственным интеллектом и машинным обучением.
Ключевые слова: нейросетевые алгоритмы, библиотеки, обучение, глубокое обучение, математические вычисления, сети, отличия.
Библиотеки для нейросетевых алгоритмов
- TensorFlow: TensorFlow[4] является одной из наиболее популярных библиотек для разработки нейросетевых алгоритмов. Она обладает широким спектром функциональных возможностей и поддерживает различные типы нейронных сетей.
- PyTorch: PyTorch[5] предоставляет гибкую и интуитивно понятную платформу для создания нейронных сетей. Она широко используется в академических и исследовательских целях и обладает простым синтаксисом.
- Keras: Keras является высокоуровневым интерфейсом для разработки нейронных сетей. Он обладает простым и интуитивно понятным API, что делает его идеальным выбором для начинающих.
- Caffe: Caffe специализируется на обработке изображений и глубоком обучении. Он обладает быстрым выполнением и широким набором предварительно обученных моделей.
Этапы нейросетевого моделирования
- Постановка задачи
- Выбор источника обучающей выборки
- Выбор архитектуры нейронной сети для решения задачи
- Определение структуры нейронной сети (кол-во и тип входных и выходных данных, количество скрытых слоев)
- Подготовка обучающей выборки
- Выбор алгоритма обучения
- Проведение обучения нейросетевой модели
- Оценка адекватности работы модели
- Применение нейросетевой модели на практике
RAG, или при чём тут GigaChat
LLM, такие как GigaChat или СhatGPT, обучаются на огромных объёмах данных. Это позволяет им генерировать текст, близкий к написанному человеком. Однако при попытке получить ответ на запрос по теме, не встречающейся в тренировочной выборке, мы получаем вымышленный ответ.
Можно попробовать дообучить модель, но это довольно бессмысленно: скрейпер — программа для автоматического извлечения данных с веб-страниц — каждый раз собирает разные данные. Для такой ситуации и подходит RAG. RAG — альтернативный способ передачи новой информации в LLM. Запрос в LLM формируется на основе отобранных текстов из базы документов. Подробнее об этом можно почитать тут.
В нашем случае из текстов, полученных при парсинге, формируется набор документов. Во время запроса производится векторный поиск по базе документов и выбираются ближайшие, на основе которых дальше запускаем семантическое ранжирование. Основной инструмент, который мы использовали для этого этапа, — chromadb.
Отобранные тексты и запрос отправляются в LLM для генерации поля карточки. В качестве LLM протестировали open source модели Vicuna-13b и LLama-13b, но лучший результат получили с помощью GigaChat Pro.
Для сравнения сгенерировали карточки каждой моделью. Далее проверяли, соответствуют ли данные из карточки реальному значению. Результаты показали, что ответы Vicuna и LLama близки к ожидаемому результату лишь в 10 случаях из 47. Тогда как GigaChat приводит правильные ответы в 35 случаях из 47.
Для работы с LLM GigaChat мы использовали GigaChain (SDK) — форк библиотеки LangChain, который адаптирован для работы с русским языком с поддержкой GigaChat API. Примеры применения RAG можно посмотреть здесь.
Нейросети в бизнес-аналитике
Бизнес-аналитика (Business Intelligence, BI) сочетает бизнес-анализ, интеллектуальный анализ данных, визуализацию данных, инфраструктуру, инструменты данных и другие практики.
Бизнес-аналитик (Business Analyst, BA) — специалист, который:
- оптимизирует текущие бизнес-процессы;
- помогает в запуске новых продуктов, услуг;
- взаимодействует с внешними и внутренними заказчиками;
- находит слабые места в бизнесе.
Встраивайте GigaChat API в свои проекты
50 000 токенов
Генерация текста GigaChat Pro
950 000 токенов
Генерация текста GigaChat Lite
![]()
Аналитик работает с информацией, которая приходит из различных источников. Среди них веб-сервисы, базы данных (БД), внешние и внутренние системы. На крупных проектах приходится взаимодействовать с гигабайтами данных разного формата, и внедрение искусственного интеллекта помогает автоматизировать рутинные процессы.
Бизнес-аналитику часто связывают со сферой IT. Business Analyst изучает требования заказчика, ведёт и поддерживает техническую документацию, взаимодействует с разработчиками продукта или сервиса и т. д.
Но в широком смысле BI — это набор программных возможностей для доступа к данным и их изучения, а затем принятия решений. Инструменты аналитики востребованы не только в IT. Их используют в:
- производстве;
- логистике;
- HR;
- бухгалтерии и финансах;
- телекоме.

Создание новых идей удержания клиентов
Аналитики в области IT часто работают со следующими задачами:
- проведение CustDev (Customer Development, обратная связь пользователей);
- UX-интервью (исследование клиентского взаимодействия с сервисом);
- построение Customer Journey Map (CJM, карта пути клиента);
- создание UserStory (пользовательские истории, короткие описания функциональности системы);
- веб-аналитика в Яндекс.Метрике и Google Analytics.
Перечисленные задачи связаны с удержанием или привлечением пользователей. Ежедневную рутину BA можно автоматизировать с помощью искусственного интеллекта и технологий машинного обучения. К примеру, генеративная нейросетевая модель GigaChat поможет:
- выделить и сегментировать аудиторию для CustDev;
- составить вопросы для Customer Development или UX-интервью;
- разработать персон для Customer Journey Map — детальные портреты типичных клиентов;
- сформулировать гипотезы для валидации;
- определить сценарии взаимодействия в CJM и стадии жизненного цикла клиента.
Искусственный интеллект можно попросить сгенерировать новые идеи привлечения или удержания клиентов (с учётом имеющейся информации о пользователях, их предпочтениях).
Что получилось в итоге
Наше решение позволяет искать информацию о конкурентах и формировать карточки с их данными в автоматическом режиме при помощи нейросетевой модели GigaChat. Мы уже достигли достойных результатов качества, но впереди еще много работы по улучшению и расширению полей карточек конкурентов. В качестве примера покажу пару подобных сгенерированных демо-карточек.
Redis
2. Короткое описание | Redis — это хранилище структур данных в памяти с открытым исходным кодом, которое используется в качестве базы данных «ключ-значение», кэша и брокера сообщений. Оно обладает высокой скоростью работы и может быть использовано в различных сценариях, включая no-code/low-code платформы. |
3. Длинное описание | Redis (Remote Dictionary Server) — это хранилище структур данных в памяти с открытым исходным кодом, используемое в качестве базы данных «ключ-значение», кэша и брокера сообщений. Оно обеспечивает высокую скорость вычислений и гибкие структуры данных, что делает его мощным инструментом для разработки приложений. Redis обладает высокой масштабируемостью и способен поддерживать крупномасштабные приложения. Он также отличается от традиционных реляционных баз данных своей функциональностью Pub/Sub и возможностью работы в режиме in-memory. Redis повышает ценность платформ no-code/low-code, предоставляя быстрый доступ к данным и упрощая процесс разработки. |
У Redis нет конкретного производителя, так как это проект с открытым исходным кодом, над которым работает сообщество разработчиков. | |
5. Технологический стек | Redis разработан на языке программирования Си (C). |
6. Актуальная версия | Последняя актуальная версия Redis — 6.2.6. Однако стоит учесть, что версии программного обеспечения могут меняться, поэтому всегда рекомендуется проверять наличие обновлений на официальном сайте продукта или в соответствующем репозитории. |
Redis используется для кэширования и хранения данных. Он также может быть использован для очередей сообщений и других задач. | |
8. Сильные стороны | Сильные стороны Redis делают его популярным выбором для управления данными в веб-разработке и других отраслях. Некоторые из его ключевых особенностей и преимуществ: 1. Молниеносная производительность: Redis работает как хранилище данных в памяти, что обеспечивает чрезвычайно быстрые операции чтения и записи, обычно в диапазоне менее миллисекунды. Это делает его идеальным выбором для 2. Поддержка различных типов данных: Redis поддерживает различные типы данных, включая строки, списки, наборы, хеш-таблицы и упорядоченные наборы, что делает его гибким и мощным инструментом для обработки и хранения различных типов данных. 3. Масштабируемость: Redis обладает высокой масштабируемостью и способен поддерживать крупномасштабные приложения. Он также поддерживает репликацию данных и кластеризацию для обеспечения высокой доступности и отказоустойчивости. 4. Функциональность Pub/Sub: Redis предоставляет функциональность Pub/Sub, которая позволяет эффективно обрабатывать события и сообщения в реальном времени. Это делает его идеальным для приложений, требующих обработки большого количества событий или сообщений. 5. Простота использования: у Redis простой и понятный синтаксис, что делает его легким в освоении и использовании. Он также предоставляет множество инструментов и библиотек для работы с различными языками программирования. 6. Открытый исходный код: Redis — это проект с открытым исходным кодом. Это означает, что он доступен для всех и может быть свободно использован и модифицирован. Это также способствует его популярности и поддержке сообщества. В целом, Redis предлагает высокую производительность, гибкость и масштабируемость, что делает его мощным инструментом для управления данными в различных сценариях. |
9. Совместимые продукты | Redis — это система управления базами данных, которая широко используется в разработке программного обеспечения. С ней совместимо множество продуктов: 1. Caché — система управления базами данных, которая может быть использована вместе с Redis для кэширования данных. 2. CouchDB — система управления базами данных, которая может быть использована вместе с Redis для хранения данных. 3. IMS — система управления базами данных, которая может быть использована вместе с Redis для обработки транзакций. 4. DB2 — система управления базами данных, которая может быть использована вместе с Redis для хранения и обработки данных. 5. Firebird — система управления базами данных, которая может быть использована вместе с Redis для хранения и обработки данных. 6. FoundationDB — система управления базами данных, которая может быть использована вместе с Redis для хранения и обработки данных. 7. Informix — система управления базами данных, которая может быть использована вместе с Redis для хранения и обработки данных. 8. Ingres — система управления базами данных, которая может быть использована вместе с Redis для хранения и обработки данных. 9. Interbase — система управления базами данных, которая может быть использована вместе с Redis для хранения и обработки данных. 10. MS SQL Server — система управления базами данных, которая может быть использована вместе с Redis для хранения и обработки данных. 11. MongoDB — система управления базами данных, которая может быть использована вместе с Redis для хранения и обработки данных. 12. MySQL — система управления базами данных, которая может быть использована вместе с Redis для хранения и обработки данных. 13. Neo4j — система управления базами данных, которая может быть использована вместе с Redis для хранения и обработки данных. 14. Oracle Database — система управления базами данных, которая может быть использована вместе с Redis для хранения и обработки данных. 15. PostgreSQL — система управления базами данных, которая может быть использована вместе с Redis для хранения и обработки данных. 16. Sybase ASE — система управления базами данных, которая может быть использована вместе с Redis для хранения и обработки данных. 17. Teradata Database — система управления базами данных, которая может быть использована вместе с Redis для хранения и обработки данных. 18. Yandex Database — система управления базами данных, которая может быть использована вместе с Redis для хранения и обработки данных. Это лишь некоторые из совместимых с Redis продуктов. Существует множество других систем управления базами данных, которые могут быть использованы вместе с Redis в зависимости от конкретных потребностей и требований проекта. |
Сайт документации Redis. Там вы найдете подробную информацию о Redis, его командах, возможностях и настройках. |
Microsoft SQL Server
Microsoft SQL Server | |
|---|---|
2. Короткое описание | Microsoft SQL Server — это система управления базами данных, разработанная компанией Microsoft. Она предоставляет инструменты для хранения, обработки и анализа данных. SQL Server широко используется в различных отраслях, включая информационные технологии, финансы, здравоохранение и розничную торговлю. |
3. Длинное описание | Microsoft SQL Server — это система управления базами данных, разработанная компанией Microsoft. Она предоставляет мощные инструменты для создания, управления и обработки баз данных. SQL Server позволяет хранить и обрабатывать большие объемы данных, обеспечивая высокую производительность и надежность. Одна из ключевых особенностей SQL Server — способность работать с различными типами данных, включая текстовые, числовые, временные и бинарные данные. Система также поддерживает различные типы индексов и позволяет создавать SQL Server также предоставляет широкий спектр инструментов для обеспечения безопасности данных, включая аутентификацию пользователей, шифрование данных и управление доступом к базам данных. Кроме того, SQL Server поддерживает работу в режиме реального времени, что позволяет обрабатывать данные в режиме онлайн. Это особенно полезно для приложений, которые требуют быстрой обработки данных, таких как интернет-магазины или системы управления контентом. В целом, Microsoft SQL Server — это мощная и надежная система управления базами данных, которая может быть использована для решения широкого спектра задач в области обработки и хранения данных. |
Производитель Microsoft SQL Server — компания Microsoft. | |
5. Технологический стек | Microsoft SQL Server разработан на основе технологии реляционных баз данных и использует язык запросов Transact-SQL — реализацию стандарта ANSI/ISO SQL с расширениями. Transact-SQL предоставляет возможность создавать, изменять и удалять данные, а также выполнять сложные запросы к базе данных. Кроме того, Microsoft SQL Server использует различные технологии для обеспечения высокой производительности, масштабируемости и надежности, такие как механизм управления транзакциями, кеширование данных, репликация и т. д. |
6. Актуальная версия | Последняя актуальная версия Microsoft SQL Server — 2019. Выбор версии SQL Server зависит от ваших потребностей и совместимости с другими системами. |
Microsoft SQL Server — это система управления базами данных (СУБД), разработанная компанией Microsoft. Она предоставляет широкий спектр функциональности, включая: 1. Хранение и управление данными: 2. Обработка запросов: 3. Транзакции: 4. Безопасность: 5. Резервное копирование и восстановление: 6. Администрирование: 7. Расширяемость: Это лишь некоторые из основных функций SQL Server. Конкретные возможности могут варьироваться в зависимости от версии и конфигурации системы. | |
8. Сильные стороны | У Microsoft SQL Server несколько сильных сторон,которые ценят компании и разработчики. Одна из них — отказоустойчивость. SQL Server позволяет создавать кластеры серверов, которые будут работать с одним экземпляром СУБД. Если какая-то машина выйдет из строя, ее |
9. Совместимые продукты | |
Сайт документации Microsoft SQL Server. Здесь вы найдете подробную техническую документацию, руководства, обучающие материалы и ресурсы для работы с SQL Server. |
Заключение
Нейросетевые алгоритмы представляют собой мощный инструмент для решения различных задач в области машинного обучения. Их разнообразие и гибкость позволяют применять их в различных областях, таких как компьютерное зрение, обработка естественного языка, рекомендательные системы и другие. Использование математических концепций и библиотек позволяет разрабатывать и оптимизировать эффективные модели. Однако, перед использованием нейросетевых алгоритмов, необходимо тщательно изучить их особенности и выбрать наиболее подходящий алгоритм для конкретной задачи.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.
- Nielsen, M. (2015). Neural Networks and Deep Learning.
- Chollet, F. (2018). Deep Learning with Python. Manning Publications.
- Abadi, M., et al. (2015). TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems.
- Paszke, A., et al. (2019). PyTorch: An Imperative Style, High-Performance Deep Learning Library.
- LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521(7553), 436-444.
- Brownlee, J. (2020). Neural Networks from Scratch: Step by Step with Python.
Интересная статья? Поделись ей с другими:
Выводы
Мы рассмотрели в общем виде, как происходит нейросетевое моделирование. Данный алгоритм применим не только для простых задач. Его можно масштабировать и использовать для обучения сложных моделей с множеством параметров.
Чтобы избежать детских ошибок, от которых не застрахованы даже крупные компании (подробнее в статье), обратите внимание на этап корректной постановки задачи, выбора источника данных для обучающей выборки и подготовки самой обучающей выборки. Заменить структуру сети или метод обучения зачастую гораздо легче, чем собирать данные для обучения или в самом конце осознать, что формулировка задачи некорректна.