

Проверьте свой английский и получите рекомендации по обучению
- Введение
- Прогнозирование SEO-трафика Google Analytics 4 с помощью Python и Prophet
- Исправление ошибки тега Google Аналитика
- Байесовский подход
- Интеграция Яндекс.Метрики c Yandex Cloud (Метрика Про)
- Тест Стьюдента
- Как успешно провести распродажу в fashion-ритейле
- Понравилась статья?
- Аналитика пиратов XXI века
- Как решить, сколько человек нужно в штате магазина
- Воронки и когорты на данных Яндекс.Метрики
- Применение NumPy в маркетинге и поведенческой аналитике
- Материалы для самостоятельного изучения
- Тест перестановок
- Практические примеры
- NumPy для продуктовой аналитики
- Расширенные возможности NumPy
- Как найти проекты для портфолио аналитикам
- Сеансов меньше, чем пользователей. Кейс по устранению
- Бутстрап
- Простое сравнение средних
- Что выгоднее – собственная техника или транспортная компания
- Тест Манна-Уитни
- Что такое кейс
- Проекты на стыке Data Science и другой экспертизы
- Советы по созданию пет-проекта
- Публикация пет-проекта
- Математический расчет поведенческих факторов в Яндекс.Метрике
- Анализ сайта и поиск ошибок в настройке событий электронной торговли
- Идеи проектов для аналитиков и дата-сайентистов
- Заключение
Введение
Что такое NumPy и почему это важно для аналитиков данных?
NumPy, сокращение от Numerical Python, представляет собой высокопроизводительную библиотеку для работы с числовыми данными в языке программирования Python. Ее важность для аналитиков данных заключается в том, что NumPy предоставляет эффективные инструменты для выполнения операций над массивами данных, что в свою очередь обеспечивает быстрый и удобный анализ больших объемов информации.
Краткий обзор Python как инструмента для аналитики данных
Python, с его простым и читаемым синтаксисом, стал предпочтительным языком для анализа данных. Благодаря множеству библиотек, таких как NumPy, аналитики получают мощные инструменты для обработки и анализа данных.

Прогнозирование SEO-трафика Google Analytics 4 с помощью Python и Prophet
08 августа, 2022

Исправление ошибки тега Google Аналитика
16 июня, 2022
Байесовский подход
Предположим, что метрика имеет известное распределение. Тогда можно по данным на предпериоде определить какое значение среднего является наиболее вероятным и какой у него доверительный интервал. Тоже самое можно проделать и для постпериода. Тогда сравнив два доверительных интервала можно сделать вывод о их различии. Альтернативно, можно посчитать вероятность увидеть данные постпериода, при фиксированных параметрах распределения на предпериоде. Такой подход может быть эффективным, если правильно угадать форму и тип распределения данных даже при очень не больших выборках.
Хороший пример и объяснение такого подхода можно найти на странице проекта pymc, а подробный разбор выходит далеко за рамки данной статьи. Далее в примере мы генерировали из нормального распределения, однако, на деле будет не лишним убедиться, что метрика и правда распределена нормально (или же иначе в зависимости от вашей гипотезы).


Доверительный интервал для предпериода: (99.48, 100.89)
Доверительный интервал для постпериода: (94.03, 95.50)
Интервалы не пересекаются, различие статистически значимо
Интеграция Яндекс.Метрики c Yandex Cloud (Метрика Про)
08 августа, 2023
Тест Стьюдента
t-тест, является одним из наиболее широко используемых и эффективных методов для сравнения средних значений. При его применении важно проверять условия, при которых ему можно доверять:
Проверить можно визуально, с помощью, например, QQ-plot, либо с помощью тестов на распределение (Шапиро-Вилка, Колмогорова-Смирнова, и других). Если одно из условий нарушено, то нужно применять другие методы
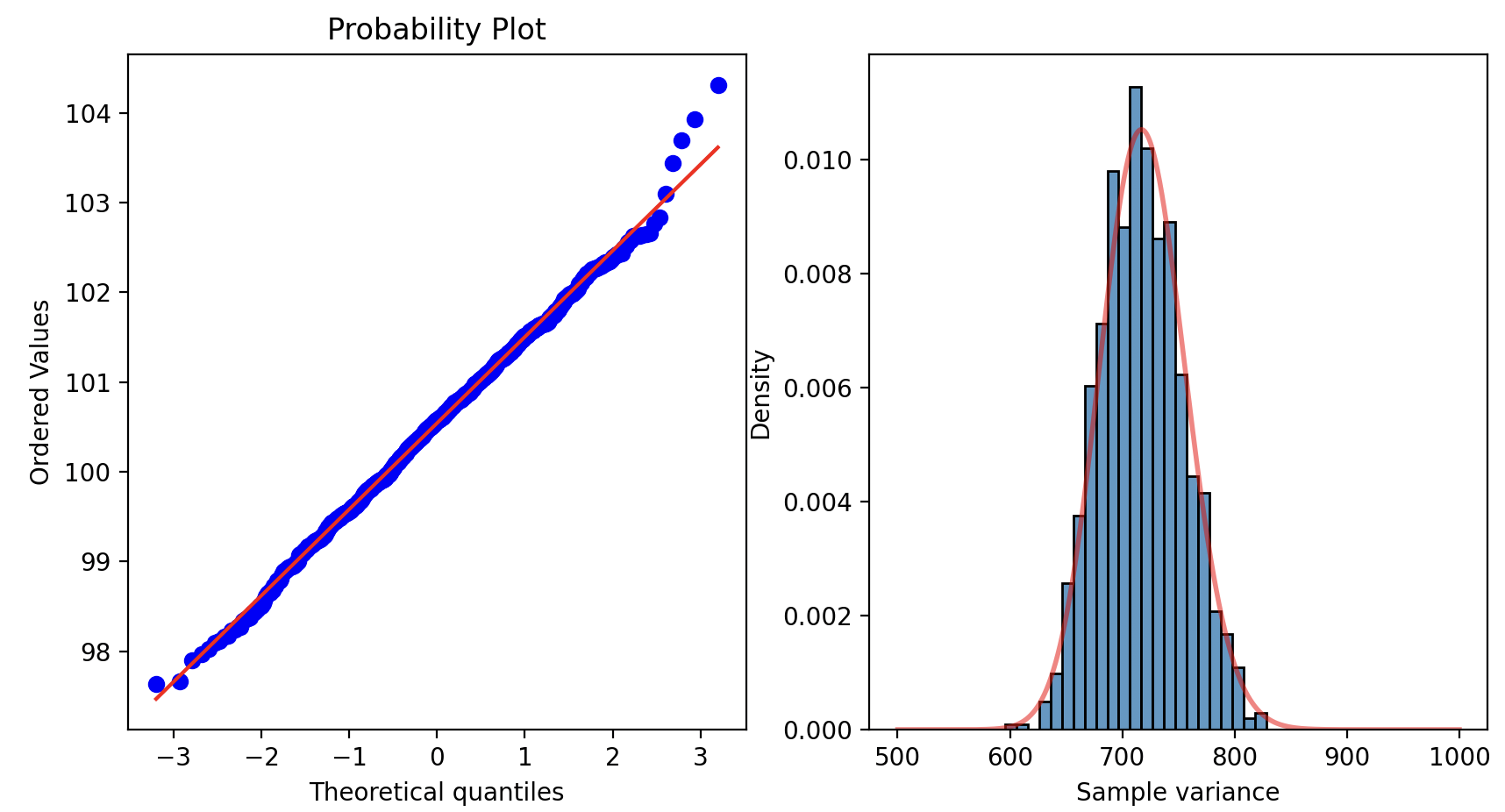
Визуальная проверка условий t-test
В рассмотренном случае различия статистически значимы.
Как успешно провести распродажу в fashion-ритейле
Сеть fashion-ритейла в сегменте lux брендов проводила кампании распродаж и промоакций. При планировании скидок и распродаж компании нужно было четко понимать финансовый результат.
В сегменте fashion-ритейла есть особенность: коллекция закупается заранее и в валюте. Поэтому, когда принимается решение о распродаже, нужно единовременно иметь на руках всю информацию: стоимость коллекции на данный момент в валюте, стоимость коллекции на момент покупки в валюте, пересчет в рубли, а также рублевую и валютную маржу.
Если не продать текущую коллекцию, не будет оборотных средств для покупки следующей, а если продать текущую коллекцию по невыгодным для ритейлера условиям, может не хватить оборотных на новую. При этом надо держать в голове, что текущую коллекцию покупали по одному курсу, следующую будут покупать по-другому. А чтобы сделать скидку, нужно видеть всю стоимость в рублях.
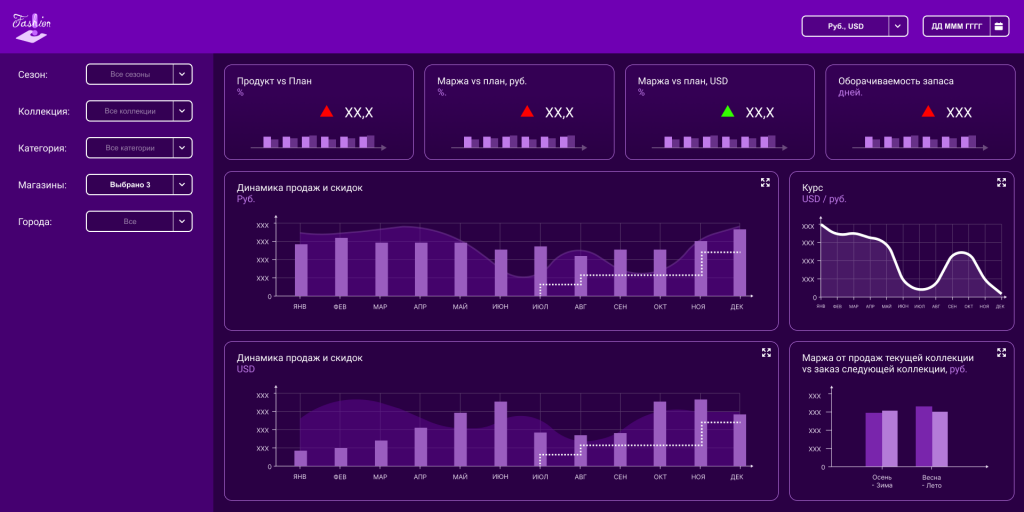
Вся эта информация, собранная и представленная в одном месте, помогает коммерческому директору принять решение об оптимальной сумме скидки. Для этого мы создали BI-инструмент, в котором данные видны на одном экране. Они ежедневно пересчитываются в автоматическом режиме. Таким образом, в любой момент можно принять правильное решение о распродаже, которое основывается на данных.
Почему данные есть, а пользы – нет
Даже красивые отчеты и дашборды иногда не помогают компании достичь целей, а менеджеру заслужить премию. Так происходит, когда отчет содержит статистику, не привязанную к действиям самого сотрудника. Как если бы в машине вместо спидометра выводилось количество штрафов за превышение скорости. Пользователь вынужден додумывать эту связь и искать самостоятельно дополнительную информацию, на что почти никогда нет времени. Поэтому даже если такой отчет и смотрят, то реального влияния на бизнес он не оказывает.
Чтобы получать пользу от BI-системы, данные в ней должны быть представлены в максимально готовом виде. Иными словами, однозначно подтверждатьопровергать гипотезу или призывать к четкий действиям. Чтобы отчет для ритейлера был таким, перед автоматизацией нужно ответить на вопросы:
Из ответов на эти вопросы выстраивается цепочка: «данные призывают к действию, действие дает результат». Как в примере с машиной: спидометр показывает, что я превышаю разрешённую скорость, я нажимаю не педель тормоза и не получаю штраф.
Другой секрет состоит в том, чтобы нужные данные оказались у правильного человека и позволили решить его рабочую проблему в персональной зоне ответственности. Например, показывать HR-директору данные по неэффективности логистики бесполезно, так как это не связано с его KPI. Но если дать ему понятный инструмент, который позволит снизить текучесть или ускорить подбор, то он будет пользоваться им без дополнительной мотивации и контроля.
Чтобы данные были полезны бизнесу, нужно посмотреть на них с точки зрения пользователей. Обрисовать картину — кто, какие задачи и где пытается решить, чего хотят акционеры или руководитель, что конкретно нужно улучшить, и в идеале – какой KPI поднять.
И после этого вы поймете, как это делать и что нужно отразить в отчете BI-системы. Дальше — дело техники.
Понравилась статья?
15 января, 2024
Новая история о том, как Яков Михайлович очередного организатора складчины разоблачил.

Аналитика пиратов XXI века
10 января, 2023

Как решить, сколько человек нужно в штате магазина
Cети супермаркетов и магазинов у дома необходимо было решить вопрос со штатным расписанием торговых точек. Обычно количество персонала напрямую связывается с объемом продаж конкретного магазина: чем больше товаров продается, тем больше сотрудников — мерчандайзеров, кладовщиков, кассиров — там нужно.
Решение о количество штата в торговой точке обычно принималось руководством на общей встрече, где присутствовали представители различных подразделений – от HR-службы до финансового и операционного департаментов. На основании того, в каком магазине сколько продаж было в последнее время, они определяли, нужно ли менять расписание.
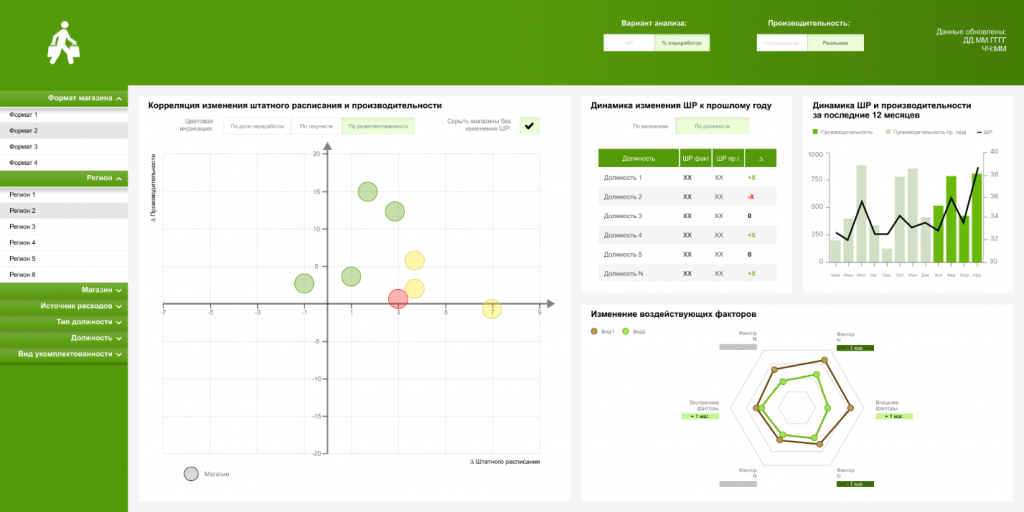
Тут есть риск: можно решить, что, если у торговой точки упали продажи, надо сразу сокращать персонал, чтобы уменьшить расходы и вернуться на уровень нужной маржинальности. При этом меньшее количество персонала ведет к понижению уровня обслуживания, что приводит к оттоку части клиентов. Продажи снова падают, штат снова сокращают.
Чтобы избежать такой ситуации, руководство решило обратиться к данным. В рамках BI-системы мы создали единую информационную панель, предназначенную для этого совещания. На дашборде по каждому магазину можно посмотреть статистику за длительный срок и корреляцию между персоналом и продажами. Туда же добавлена информация о внешних факторах, влияющих на магазин, в том числе о конкурентных торговых точках, расположенных рядом.
На основании полной информации комитет, встречающийся на этих заседаниях, может принимать взвешенные решения о снижении или росте штата.
Воронки и когорты на данных Яндекс.Метрики
22 мая, 2023

Применение NumPy в маркетинге и поведенческой аналитике
Сегментация клиентов с помощью NumPy
Предположим, у нас есть данные о покупках клиентов, и мы хотим разделить их на группы по сумме покупок:
Анализ эффективности рекламных кампаний
Допустим, у нас есть данные по кликам и конверсиям. Мы можем использовать NumPy для вычисления конверсии:
Материалы для самостоятельного изучения
Kaggle — это бесплатный сервис, который позволяет участвовать в соревнованиях для аналитиков, общаться с дата-сайентистами, изучать машинное обучение и просто вдохновляться. Многие компании обращают внимание на место соискателя в пользовательском рейтинге, поэтому ссылку на Kaggle часто добавляют в резюме.
Data Science Pet Projects. FAQ — подробная статья о пет-проектах для дата-сайентистов из блога крупнейшего русскоязычного Data Science сообщества.
С чего начать изучение анализа данных и где найти идеи для первых проектов — статья в блоге Практикума. В ней мы рассказываем, какие источники использовать при изучении анализа данных, как развиваться в аналитике и сколько можно зарабатывать.
Тест перестановок
В некотором смысле похож на бутстрап, но позволяет работать с выборками разного размера, хотя более вычислительно сложный. Если бутстрап на практике хорошо работает с 1000 итераций семплирования, то для теста перестановок нужно примерно 100000 итераций (подробнее описано в книге Bootstrap Methods And Permutation Tests Companion Chapter 18 To The Practice Of Business Statistics).
Тест перестановок основан на идее того, что при справедливости нулевой гипотезы распределение данных не изменится при случайных перестановках меток групп. Таким образом, сравнение наблюдаемого значения с распределением, полученным путем перестановок, позволяет делать выводы о статистической значимости различий между группами.
P-значение для перестановочного теста много меньше 0.05. Различие статистически значимо (alpha = 0.05).
Практические примеры
Реальные кейсы использования NumPy в маркетинговой аналитике
Представим, у нас есть данные о рекламных кампаниях. Каждая кампания имеет свою стоимость и количество кликов. Мы можем использовать NumPy для расчета стоимости клика:
Рассмотрим более комплексный сценарий, который включает в себя дополнительные аспекты анализа рекламных кампаний.
В данной части кода мы импортируем библиотеку NumPy и задаем данные о рекламных кампаниях, такие как стоимость, количество кликов, конверсии и доход с каждой конверсии. Затем мы рассчитываем стоимость клика для каждой кампании и выводим результаты:
А теперь мы проводим дополнительные расчеты, такие как общая стоимость рекламных кампаний, общее количество кликов и конверсий. Результаты этих вычислений выводятся для анализа и последующего использования в расчетах средней стоимости клика, конверсионной ставки и среднего дохода с клиента.
# Расчет общей стоимости кампании
total_campaign_cost = np.sum(campaign_costs)
print(«Общая стоимость рекламных кампаний:», total_campaign_cost)
# Общая стоимость рекламных кампаний: 1300
# Расчет общего количества кликов и конверсий
total_clicks = np.sum(clicks)
total_conversions = np.sum(conversions)
print(«Общее количество кликов:», total_clicks)
# Общее количество кликов: 6500
print(«Общее количество конверсий:», total_conversions)
# Общее количество конверсий: 185
В заключении мы рассчитываем среднюю стоимость клика (CPC), долю конверсий (CR) и средний доход с клиента (ARPU).
# Расчет средней стоимости клика, конверсии и дохода с клиента
average_cost_per_click = np.mean(cost_per_click)
conversion_rate = total_conversions / total_clicks
average_revenue_per_customer = np.sum(revenue_per_conversion * conversions) / total_conversions
print(«Средняя стоимость клика:», average_cost_per_click)
# Средняя стоимость клика: 0.225
print(«Доля конверсий:», conversion_rate)
# Доля конверсий: 0.02846153846153846
print(«Средний доход с клиента:», average_revenue_per_customer)
# Средний доход с клиента: 56.75675675675676
В этом расширенном кейсе мы учитываем не только стоимость кликов, но и общую стоимость кампаний, общее количество кликов и конверсий, среднюю стоимость клика, конверсионную ставку и средний доход с клиента. Такой анализ может быть полезен для более глубокого понимания эффективности рекламных кампаний.
Шаг за шагом: анализ данных продаж с NumPy
Допустим, у нас есть данные о продажах за неделю. Мы можем использовать NumPy для вычисления общей суммы продаж и средней цены продажи:
NumPy для продуктовой аналитики
Отслеживание и анализ пользовательского поведения
Рассмотрим сценарий, где у нас есть данные о времени, проведенном пользователями на платформе. Мы можем использовать NumPy для анализа распределения времени:
Оптимизация продуктовых стратегий на основе данных
Допустим, у нас есть данные о частоте использования ключевых функций продукта. Мы можем использовать NumPy для выявления наиболее популярных функций:
Расширенные возможности NumPy
Интеграция NumPy с другими библиотеками Python для аналитики
NumPy часто используется в сочетании с Pandas для работы с табличными данными и Matplotlib для визуализации результатов. Например:
Сложные статистические анализы с NumPy
Для проведения сложных статистических анализов, таких как корреляции между различными переменными, можно использовать функции NumPy:
Как найти проекты для портфолио аналитикам
Время на прочтение
Если вы начинающий специалист и ищете работу, скорее всего, вы уже знаете, что при трудоустройстве требуют не только резюме и сопроводительное письмо. Очень часто просят показать какие-то реальные рабочие кейсы. Но где брать кейсы, если опыта мало?
Наставники курса «Аналитик данных» расскажут, как находить проекты для портфолио аналитикам, дата-сайентистам и вообще всем, кто связан с датой. В этой статье читайте:
Сеансов меньше, чем пользователей. Кейс по устранению
18 февраля, 2022
Кейс по устранению проблемы, приводившей к серьезному искажению данных в отчетах Universal Analytics. Подробное описание диагностики и устранения неполадок.
Бутстрап
Основная идея — генерировать 1000 новых датасетов из исходного случайным сэмплированием с повторениями и определить доверительный интервал через квантили. Применимость бутстрапа очень широка, это связано с тем, что он не требует нормальности распределения средних случайной величины. Бутстрап позволяет построить как доверительные интервалы для пост периода и предпериода в отдельности, так и интервал для разности средних. Если доверительный интервал разности средних не содержит 0, то разница статистически значима. Хорошее описание приведено в книге Efron B. Bootstrap confidence intervals for a class of parametric problems, Biometrika 1985.
Когда выборка содержит выбросы или неточности, бутстрап может обеспечить устойчивость при оценке параметров модели, так как этот метод создает множество подвыборок, в каждой из которых могут быть учтены различные комбинации данных, включая выбросы. Анализ статистик, полученных из этих подвыборок, может предоставить информацию о диапазонах возможных значений параметров и их доверительных интервалах.
Однако стоит отметить, что бутстрап не гарантирует полное устранение влияния выбросов или грязи в данных, а также плохо работает на маленьких выборках. В некоторых случаях выбросы могут сохраняться в различных подвыборках, и они могут по-прежнему влиять на оценки модели. Бутстрап предоставляет инструмент для более устойчивой оценки, но не является универсальным средством решения всех проблем с выбросами или неточностями в данных.
Тем не менее, важно, что если исходные данные содержат систематическую зависимость или нарушение независимости (например, временные зависимости), бутстрап может не учитывать этот аспект. В таких случаях более тщательные методы, специфичные для типа данных, могут потребоваться для учета зависимости между наблюдениями.

Доверительный интервал для постпериода: (94.03, 95.58)
Доверительный интервал для предпериода: (99.28, 100.73)
Доверительный интервал для разницы средних: (-6.19, -4.20). Различия статистически значимы.
Простое сравнение средних
Первая идея — найти среднюю на пред периоде, среднюю на пост периоде и сравнить.
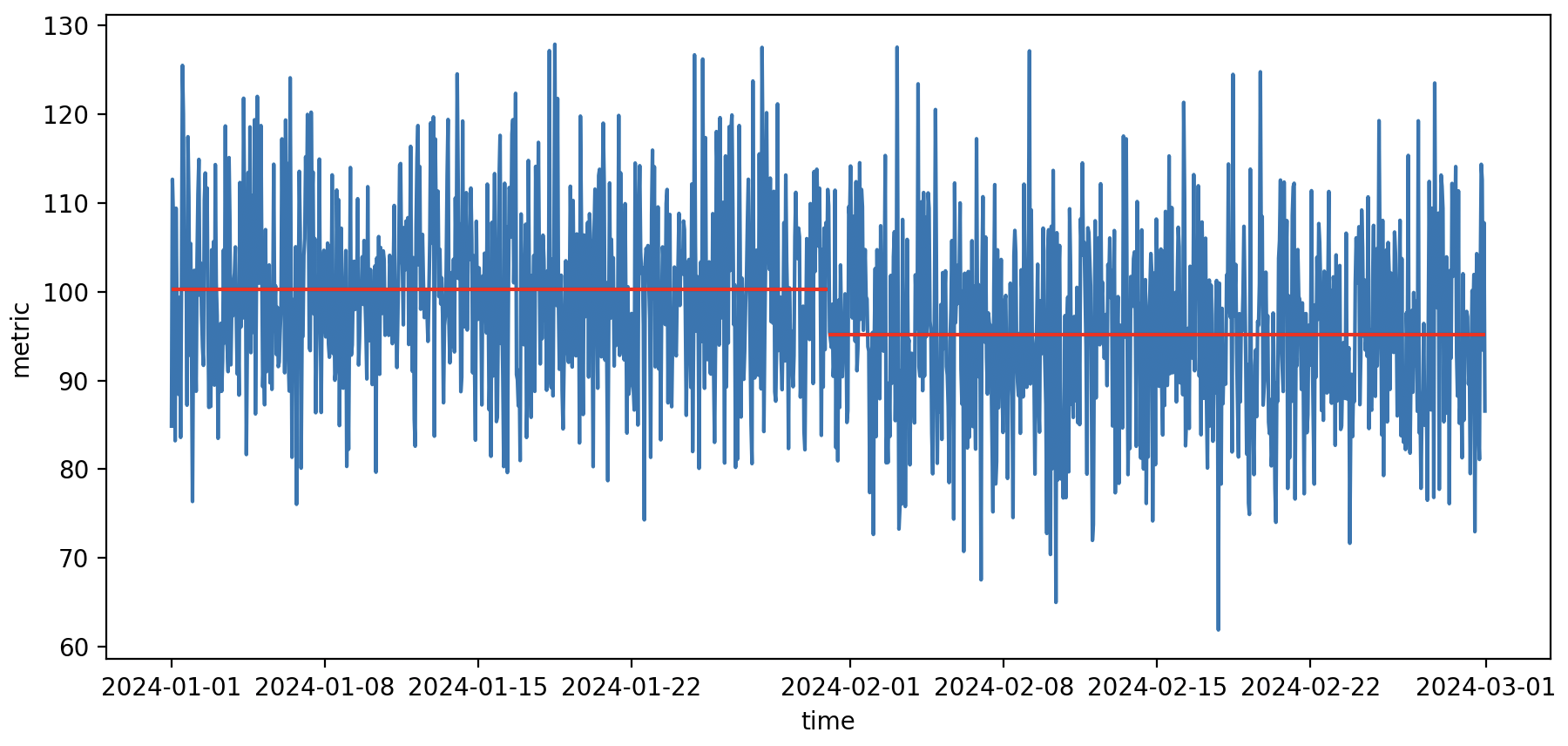
Сравнение метрики для двух соседних месяцев через сравнение средних
Даже при отсутствии реальной разницы между средними значениями, вероятность того, что два средних совпадут практически нулевая. В половине случаев правая средняя будет меньше, просто из-за случайных колебаний. Рассмотрим несколько возможных подходов для более объективного анализа.
Что выгоднее – собственная техника или транспортная компания
Региональная продуктовая сеть класса дискаунтер каждый день перевозит товары из распределительного центра (РЦ) в торговые точки. При этом компания работает с большим количеством магазинов и РЦ и хочет сократить ежедневные затраты на логистику при помощи BI-системы.
Стоимость перевозок может быть разной. Это зависит от ряда факторов – задействованы ли собственные водители, есть ли техники по обслуживанию автомобилей в штате, собственные ли автомашины. В настоящий момент в компании перевозками занимается внешняя транспортная компания.
Можно решить, что самый эффективный вариант с точки зрения затрат – это купить собственный транспортный парк и нанять водителей. В этом случае ритейлер не платит стороннему оператору. Однако стоимость доставки сильно зависит от ее «плеча», и чем дальше магазин находится от РЦ, тем эффективнее именно привлеченный транспорт, так как удобнее выстраивать смены водителей. Со своим автопарком придется делать несколько «ходок», а с длинным «плечом» работает одна смена, о времени простоя которой можно не волноваться.
На решение также влияют изменяющиеся тарифы на перевозку, нестабильный грузопоток, который зависит от продаж в магазинах, появление новых торговых точек и РЦ. Транспортная сеть постоянно перестраивается, и решение по конкретному маршруту может меняться чуть ли не каждую неделю. Как в этой ситуации решить, свой или чужой транспорт будет эффективнее?
BI-система помогла ритейлеру регулярно собирать все данные о транспортных сетях. На основании этой информации логисты смогли заняться решением математической задачи, которая сводится к двумя цифрам – стоимости работы с собственным автопарком и стоимости работы с внешним подрядчиком. Итого, сравнивая две цифры, компания принимает взвешенное решение, которое легко можно обосновать.
Тест Манна-Уитни
Мана-Уитни, U-test. Этот тест не подходит для сравнения средних. Подробнее можно посмотреть в статье Ниже приведём пример моделирования 1000 тестов двух распределений с одинаковым средним и разными дисперсиями.
U-test систематически выдаёт большее количество ложных срабатываний (существенно больше чем в 5% случаев) чем t-test при одинаковом уровне alpha = 0.05. По похожим причинам не подходят тест Колмогорова-Смирнова и некоторые другие тесты, сравнивающие распределения случайных величин, вместо средних.
Что такое кейс
Кейс — это особая схема анализа и решения задач. Он позволяет структурировать информацию, выявлять ключевые моменты и определять последующие шаги. Такие кейсы могут использовать в различных областях: от бизнеса и управления до личной жизни и профессионального развития. Подробнее о нем — в статье.
Важно понимать, что кейсы не только помогают принимать решения, но и развивать критическое мышление, расширять кругозора и повышатьпрофессиональные навыки. Если научитесь работать с ними, сможете и эффективно решать задачи, и находить новые подходы к проблемам, учитывая различные точки зрения и факторы.Тест на уровень английскогоУзнайте свой уровень, получите рекомендации по обучению и промокод на уроки английского в подарокКейс: ключевые особенности и функцииРазберем понятие кейса в бизнес-среде. Здесь кейс — это комплексный аналитический материал, который используют, чтобы решать конкретные проблемы и искать оптимальные решения. Кейсы включают в себя описание ситуации, анализ факторов, проблем и рекомендации по решению задачи.Важная особенность кейса — это его практическая направленность. Такой инструмент помогает ознакомиться с реальными сценариями в бизнесе и применить теоретические знания в практике. Ключевая функция кейса — в обучении анализу и принятию решений в различных ситуациях, что делает его важной частью делового образования и практики. Открыть диалоговое окно с формой по клику
Особенности и предназначение кейсаОсновная цель кейса — представление практического опыта в удобной форме для дальнейшего изучения и анализа. Кейс позволяет обобщить знания, выделить ключевые моменты и принять обоснованные решения на основе проанализированных данных.Кейсы структурированы и логичны. Они должны содержать информацию о контексте, проблеме, анализе, принятых решениях и результате.Кейсы часто используют в образовательных целях, чтобы обучающиеся могли применить теоретические знания на практике и научиться принимать обоснованные решения.Кейс можно применять в различных сферах деятельности, от бизнеса и менеджмента до медицины и образования.Зачем нужны кейсыРешение проблем и анализ ситуацийКейс позволяет описать конкретную проблему или ситуацию, выделить ключевые аспекты и факторы, проанализировать возможные варианты решения и выбрать наиболее оптимальный путь действия. Этот метод помогает развивать аналитическое мышление и принимать обоснованные решения.Обучение и обмен опытомКейсы используют в образовательных программах, тренингах и семинарах для обучения и развития профессиональных навыков. Они позволяют студентам и специалистам из разных сфер делиться опытом, учиться на чужих ошибках и находить новые подходы к решению проблем.Рассмотрим плюсы и минусы такого подхода в таблице.
Проекты на стыке Data Science и другой экспертизы
Классные проекты рождаются на стыке Data Science и текущей деятельности человека или его предыдущего опыта. Если у вас есть доменная экспертиза, используйте её в свою пользу.
Если вы работаете в чём-то связанном с экономикой, вы можете проанализировать некие экономические показатели, построить экономические модели. Если вы инженер и работаете на производстве, можно подумать про обработку сигналов или изображений, классификацию чего-то.
Несколько конкретных примеров:
Советы по созданию пет-проекта
Лучше не начинать делать пет-проект до конца обучения. Обычно, если человек идёт на обучение, у него уже есть своя жизнь и работа, а учёба — это уже вторая смена. Если запараллелить ещё и создание пет-проекта — будет сложно.
Сначала стоит прокачаться, получить необходимые знания и навыки, подготовиться к созданию проекта и поиску работы. Если у вас недостаточно навыков, скорее всего, вы быстро потеряете мотивацию и решите не завершать проект. В общем, незачем распылять свои ресурсы на всё сразу — разумнее действовать очерёдно.
В идеале начинать работу над проектом лучше с сокурсниками и наставником. Сокурсники обладают разными навыками, из них может получиться большая классная команда. Наставник поможет декомпозировать задачи, дать советы по реализации, посмотреть код.
Если вы чувствуете, что у вас недостаточно навыков для серьёзных проектов, — это на самом деле классный момент. Вы уже отловили, что вам чего-то не хватает, теперь можно потратить несколько дней на проблемную тему — так вы начнёте разбираться чуть больше. Через ещё две недели, вероятно, полностью закроете этот пробел.
Публикация пет-проекта
Получается, вдобавок к статичному коду в репозитории или дашборду (его можно опубликовать, например, на Yandex DataLens) вы можете добавить приложение или телеграм-бота. Это дополнительный плюсик в вашу пользу, когда работодатель увидит, что вы и на это способны.
Математический расчет поведенческих факторов в Яндекс.Метрике
17 марта, 2023

Анализ сайта и поиск ошибок в настройке событий электронной торговли
09 апреля, 2023

Идеи проектов для аналитиков и дата-сайентистов
Необязательно придумывать что-то совершенно уникальное — обычно работодателям всё равно, насколько инновационные проекты у соискателей. Достаточно сделать проект на совесть и показать свои умения.
Если начинающий специалист может сам организовать проект, задеплоить его, найти инфраструктуру и так далее — это тоже очень важно. Это значит, что новичка не придётся обучать этим техническим деталям. Работодатели это ценят.
Не бойтесь заимствовать идеи. Поищите в интернете уже реализованные проекты и попробуйте сделать нечто похожее — результат у вас получится свой. Условно, если кто-то написал картину, это не значит, что вам не следует писать картины.
Заключение
NumPy является неотъемлемым инструментом для маркетологов и аналитиков, стремящихся к эффективному анализу данных. Эта библиотека предлагает мощные и гибкие возможности для работы с числовыми данными, что особенно ценно в сфере маркетинга и продуктовой аналитики. Использование NumPy позволяет проводить сложные вычисления, статистический анализ, сегментацию клиентов, оптимизацию рекламных кампаний и анализ продуктовой эффективности.
Интеграция NumPy с другими библиотеками, такими как Pandas и Matplotlib, усиливает его функциональность, предоставляя еще более широкие возможности для визуализации данных и анализа табличных данных. От сегментации клиентов до оптимизации рекламных стратегий, NumPy обеспечивает основу для глубокого понимания рыночных трендов и потребительского поведения.
Освоение NumPy открывает новые горизонты для маркетологов и аналитиков, стремящихся к повышению эффективности бизнес-стратегий на основе данных. Это важный навык, помогающий в извлечении значимых выводов из данных и принятии обоснованных решений.
Мы рассмотрели несколько популярных подходов, но многие современные методы, связанные с машинным обучением, остались в стороне. Например подходы causal inference, Difference in Difference, и некоторые другие методы основанные на конструировании синтетического контроля можно найти например в статье Spotify, «Causal Inference in Statistics: A Primer» by Judea Pearl, «Counterfactuals and Causal Inference: Methods and Principles for Social Research» by Stephen L. Morgan and Christopher Winship, и других.
Опытный аналитик отметит, что если есть устойчивый нисходящий тренд, то при анализе стоит учитывать этот фактор, так как в таком случае на постпериоде мы всегда увидим занижение среднего. Часть указанных выше продвинутых методов позволяют учесть тренд, но для начала нужно определить, а есть ли тренд? В следующей статье мы обсудим подходы к определению тренда и их применимость на практике.