
- Местоположение и тип занятости
- Компания
- О компании и команде
- Какие задачи вас ждут
- Осознайте, что такое фриланс в реальности
- Пример моего портфолио
- Как я получила 16 заявок?
- Какие задачи востребованы на бирже?
- Выводы
- Не Data Science единым
- Найди мотивацию и построй карьерный план
- Построй свою дорожную карту
- Шаг 1. Анализ рынка
- Шаг 2. Обучение и составление портфолио
- Шаг 3. Дообучение и поиск работы
- Подборка материалов на все случаи жизни
- Вместо послесловия
- Простое сравнение средних
- Тест Стьюдента
- Тест Манна-Уитни
- Бутстрап
- Тест перестановок
- Байесовский подход
- Заключение
- Сделают ли самостоятельные проекты меня мидлом
Местоположение и тип занятости
Полный рабочий день
Компания
Компания, которая развивает самую популярную в России поисковую систему и десятки других сервисов
О компании и команде
Яндекс Маркет обеспечивает полный фулфилмент-цикл для своих партнёров (складское хранение, приём, комплектацию и упаковку заказов, получение оплаты, доставку, работу с возвратами). Сервис предоставляет покупателям широту выбора товаров от поставщиков и гибкие условия.
Одна из важных составляющих эффективной работы такой модели — наличие быстрой и качественной доставки товаров. Сейчас мы ищем аналитика, который поможет нам построить лучшую доставку на рынке.
Мы ждём человека, который будет не просто описывать ситуации, а находить пути для улучшения процессов и помогать их внедрять.
Какие задачи вас ждут
Время на прочтение
За 7 дней я получила 16 заказов на фрилансе и в этой статье поделюсь своим опытом: как именно мне удалось это сделать, с каких ресурсов пришли заказы.
Статья будет полезна:
Осознайте, что такое фриланс в реальности
Буквально на минуту отвлекусь от опыта и вставлю свои философские 5 копеек на тему что такое фриланс на самом деле (на мой взгляд).
Почему‑то многие думают, что фриланс — это как работа на кого‑то, только с преимуществами свободного графика. Думают, что нужно просто иметь знания в конкретной области, а все остальное приложится.
Но фриланс, на мой взгляд, состоит из 4 частей:

На начальном этапе продвижение может занимать 80% всего времени и даже более. Если маркетингом заниматься не нравится или трудно, то фриланс может показаться адом.
Кроме того на более поздних этапах нужно выстраивать собственную систему: общения с заказчиками, маркетинга, принципы работы и пр. Если клиентов будет мало, если вы будете прогибаться под клиента — такой фриланс покажется рабским трудом и отличаться от работы по найму будет только в худшую сторону.
Это в случае если вы хотите вплотную заняться фрилансом и сделать его основным источником дохода. В том случае, если хотите использовать фриланс на начальных этапах для получения опыта или от случая к случаю (как дополнение к основной деятельности) — то тут конечно проще.
Пример моего портфолио
Первым шагом я создала простое портфолио в notion.
Ниже привожу портфолио «как оно было», ничего не исправляя, хотя с тех пор прошло более года.
Вначале я сделала краткое описание своей «миссии» и свои скиллы — что я умею.

Далее я описывала отдельно каждую услугу, которую я готова предоставить в формате:
Нюанс — всех клиентов в портфолио я называла «по имени», так как информация не была конфиденциальной и конкретному отдельному человеку я могла ее рассказать, но тут на всякий случай имя клиента скрываю. Мои клиенты были с предыдущих мест работы по найму. Если вы еще нигде не работали — тогда пишите учебные проекты.


В конце указала стоимость, условия сотрудничества и контакты.

Примеры портфолио других аналитиков данных приводила тут.
Как я получила 16 заявок?
Как писала выше, «маркетинг» или «самопродвижение» являются важной частью. Нужен четкий план, как получить клиентов и настроить «поток» клиентов.
Где я разместила свое портфолио?
В итоге я получила 16 заказов:
Я считаю важным размещать портфолио на как можно большем количестве площадок. В общей сложности я разместила свое портфолио на более чем 30 площадках (РФ и зарубежных). Здесь не буду перечислять все (это тема для отдельной статьи). Множество площадок можно найти простым поиском в google, причем в англоязычном пространстве вы можете найти рекомендации по площадкам в конкретной сфере — аналитике данных, маркетинге, дизайне, программировании и пр.
Также на некоторых площадках есть биржи с заданиями, где можно откликаться на понравившееся задание. Я делала это регулярно при появлении новых заданий.

Практически все полученные заказы были связаны с построением дашбордов.


Какие задачи востребованы на бирже?
Как писала выше, все поступившие заказы были связаны с дашбордами.
На втором месте на рынке РФ, на мой взгляд, задачи по настройке систем веб‑аналитики (судя по размещенным задачам на биржах).
На зарубежном рынке на биржах можно найти задачи на любой вкус — от простых задач по настройке систем веб аналитики до задач, связанных с машинным обучением.

Выводы
Сделала эту статью, так как был на нее запрос в моем телеграм канале по аналитике. Для себя же я поняла, что фриланс — это не то, чем я хочу заниматься и выбрала реализацию собственных бизнес‑проектов (некоторые из них связаны с аналитикой данных).
«План, что и говорить, был превосходный; простой и ясный, лучше не придумать. Недостаток у него был только один: было совершенно неизвестно, как привести его в исполнение».
Льюис Кэрролл, «Алиса в Стране Чудес»

Порог для входа в профессию очень высокий, так как DS стоит на стыке трех направлений: аналитики, математики и программирования. Но освоить специальность — задача выполнимая (хоть и непростая), даже если ты гуманитарий и списывал математику у соседа по парте.
В этой статье я собрала несколько рекомендаций на основе моего личного опыта (как поиска работы, так и найма людей), а также исходя из рассказов знакомых.
Не Data Science единым
В области Data есть несколько специализаций, поэтому прежде всего стоит понять, что интересно именно тебе. Почитай описание профессий (например, в этой статье), требования, обязанности и попробуй разобраться, что тебе больше всего подходит.
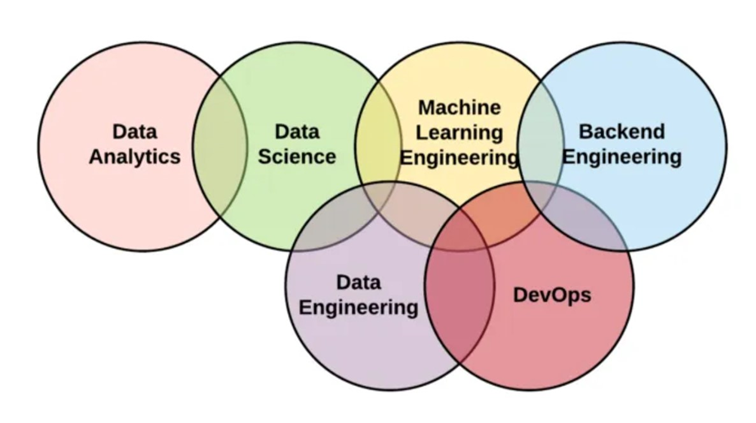
Взаимосвязь различных Data-профессий, взято из статьи
Обычно, если человек хочет попасть в Data Science, но при этом у него нет знания хотя бы одного языка программирования или математики, проще начинать с аналитики данных. Тем более, что практически всё, что требуется от аналитика данных, нужно и дата-сайнтисту.
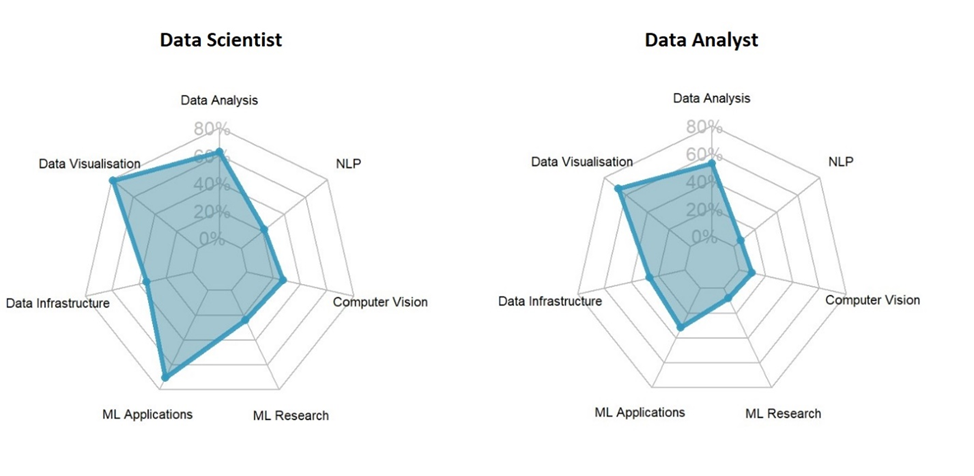
Сравнение требований для дата-сайнтиста и аналитика данных, взято из статьи
Почему именно аналитик данных? Есть разные подходы, но я всегда за то, чтобы выходить на работу как можно скорее, не тратя много времени на сугубо теоретическую часть (обучение Data Science с нуля займет как минимум полгода, в то время как на аналитика данных можно выучиться и за три месяца). Кроме того, погрузившись в область, ты можешь понять, что это вообще не твое. Как говорится, не попробуешь — не узнаешь. Так ты хотя бы не потратишь на это огромное количество усилий.
Найди мотивацию и построй карьерный план
Разберись со своей мотивацией. Какие именно потребности ты хочешь закрыть? Это, вроде бы, простой совет, но на самом деле он требует довольно серьезной психологической работы. Ответь себе, что тебе даст работа в Data Science? Деньги, причастность к миру новых технологий, удовлетворение амбиций, новые карьерные перспективы, интересные задачи? Не все эти потребности могут быть удовлетворены.
Если ты хочешь работать с новыми технологиями, то учти, что зачастую задачи бывают довольно рутинными. Не всегда используются SOTA (State of the Art) подходы, так как необходимо оглядываться на потребности бизнеса и выбирать то решение, которое будет лучше всего им соответствовать.
Также необходимо составить собственную карьерную стратегию, чтобы понимать, какую именно работу ты ищешь. Каждый человек индивидуален, поэтому важно осознать свой опыт и понять, что из него можно извлечь. Зачастую бывает проще сначала выйти на промежуточное место работы, подкопить опыта и двигаться дальше.
Например, если ты работаешь на заводе и хотел бы заниматься Data Science, то не стоит уходить далеко от тематики производства. У тебя уже есть знание специфики (это даст преимущество перед остальными соискателями), к которому надо лишь добавить некоторые технические навыки.
Делай рефрейминг опыта
Один и тот же опыт работы можно передать совершенно по-разному. И ни одна из версий не будет неправильной, так как это всего лишь взгляды с разных точек зрения. Только от тебя зависит то, что услышит потенциальный работодатель. И тут дело не только в личной выгоде, но и в уважении к другому человеку. Ты же видишь описание вакансии, так и расскажи о себе с точки зрения этой конкретной позиции. Не надо вываливать на бедного рекрутера всю историю своей жизни, чтобы он потом в этом разбирался.
Во многом это даже показывает те самые гибкость мышления и творческий подход, которые так нужны в Data Science. Часто в наших задачах нужно рассмотреть проблему с разных сторон, предложить несколько вариантов решения и проанализировать, какой из них лучше.
Вообще Data-профессии связаны с данными, которые нас окружают. Даже если твоя работа далека от Data Science, ты можешь попробовать найти в ней данные, на которых можно потренироваться.
Если ты работаешь на производстве — попробуй написать скрипты и обработать данные, провести статистический анализ, возможно, даже построить хотя бы простейшие ML-модели. В сфере продаж или при любой другой работе с клиентами можно собирать о них какие-то данные, проводить аналитику, считать корреляции параметров и строить модели. Если ты делаешь какую-то рутинную работу (например, однотипные расчеты в Excel), попытайся написать скрипт, который будет это автоматизировать — тем самым ты как минимум сэкономишь себе время на обучение.
Построй свою дорожную карту
Перейдем к практической части. Я сразу оговорюсь, что все рекомендации, которые я буду давать ниже, верны концептуально. Это база, но, возможно, какие-то детали нужно будет доработать. Это связано с тем, что вариантов вакансий масса, в каждой — своя специфика, свои решаемые задачи. Например, работа в финтехе и в биоинформатике существенно различается.
Шаг 1. Анализ рынка
Посмотри имеющиеся вакансии, постарайся определить основные требования в них (прежде всего, в части хард скиллов). Также стоит для себя определиться, готов ли ты к релокации, если, например, в твоем городе будет мало достойных предложений.
Шаг 2. Обучение и составление портфолио
В обучении важна регулярность и системность, поэтому составь расписание, ориентируясь на то, что как минимум 2-3 дня в неделю ты будешь уделять этому время. Я не советую растягивать обучение на большой промежуток времени, лучше пусть это будет несколько коротких курсов, чтобы был виден свет в конце тоннеля.
Помимо курсов, я также настоятельно рекомендую заняться профилем на GitHub. В интернете полно информации о том, как его можно оформить. Это важно, ведь когда ты новичок, тебе надо, во-первых, выделиться среди остальных, а во-вторых — показать, что ты действительно что-то умеешь и с тобой стоит разговаривать. Выхлоп от этого точно будет. Например, однажды мне не стали давать тестовое задание, сказав, что всё уже посмотрели в моем профиле.
Шаг 3. Дообучение и поиск работы
Лучше выйти на рынок труда как можно раньше, в идеале — когда ты понимаешь, что в целом уже удовлетворяешь 75% требований в вакансии. Ни в коем случае не надо пытаться выучить всё и разобраться во всём досконально. Конечно, сама по себе эта идея правильная, но это займет очень много времени, а какие-то вещи ты поймешь до конца только через несколько месяцев работы. Так что не затягивай.
Подборка материалов на все случаи жизни
На мой взгляд, в разрезе Data Science самый эффективный способ развития — самообучение. Постоянный поиск информации составляет существенную часть профессии — ты постоянно чего-то не знаешь, и это нормально. Сейчас в открытом доступе есть много качественной информации, по крайней мере, если мы говорим о базе, которая нужна для входа в профессию.
Все курсы и материалы, которые приведены ниже, — это моя личная рекомендация, они полностью бесплатны и подобраны таким образом, чтобы осилить их смог человек без математического образования (хотя это не означает, что всё будет легко). Для подготовки на аналитика данных я бы пропустила тему с машинным обучением (или ограничилась бы лишь первым курсом).
Хочу отметить, что это не исчерпывающий список. Если что-то будет непонятно или чего-то будет не хватать — гугл в помощь.
«Основы статистики» — сравнительно несложный курс по математической статистике, многие вещи объясняются «на пальцах». Также я бы добавила легкий курс «Основы комбинаторики и теории вероятностей для чайников», где можно порешать большое количество задач и набить руку.
Если есть желание углубиться в тему — материалов масса, начиная от курса «Теория вероятности» и заканчивая многочисленными лекциями на YouTube.
Здесь я порекомендую две программы:
Для аналитика данных можно ограничиться первым курсом, для дата-сайнтиста нужны оба.
Зачастую и дата-сайнтисты, и аналитики данных работают с Jupyter-ноутбуками (их еще называют тетрадками), поэтому я рекомендую посмотреть несколько обучающих видео на эту тему (работать с ними можно, например, в Google Colab или на Kaggle). Важная часть работы — проведение исследовательского анализа данных или EDA (Exploratory Data Analysis). Примеры чек-листов для EDA можно найти здесь или здесь, а примеры самого EDA — здесь или здесь.
Математика нужна для того, чтобы понимать, как работают алгоритмы машинного обучения. Я рекомендую курс «Математика для Data Science», так как он довольно компактный и содержит всю необходимую базу.
Вот мы и подобрались к самому интересному. ML — это очень глубокая тема, я бы порекомендовала взять один из курсов за «базу», а потом дополнять его различными материалами.
Разумеется, этот список далеко не исчерпывающий. Я бы порекомендовала на первых порах обратить внимание на первые четыре пункта (причем первые два — прямо обязательно), а остальное — по мере необходимости и возможности.
Если ты чувствуешь, что тебе не хватает каких-то материалов, или какая-то тема недостаточно раскрыта — ищи ее в других источниках в интернете, это крайне полезный навык.
Я объединила эти два пункта в один, так как хочу порекомендовать два видео от одного спикера — «Git. Большой практический выпуск» и «Основы Docker. Большой практический выпуск». Если что-то окажется непонятным, можно посмотреть еще другую информацию, но здесь, на мой взгляд, автор очень простым языком объясняет довольно сложные вещи.
Кстати, про Git. Если ты заведешь профиль на GitHub и будешь выкладывать туда свои проекты, то у тебя автоматически появится опыт работы с Git (только нужно работать через командную строку, а не через интерфейс).
На изучение SQL не нужно много времени, особенно, если ты знаком с библиотекой Pandas. Я бы рекомендовала оставить эту тему на последний момент, потому что без постоянной практики эти знания быстро улетучиваются. Можно пройти однодневный курс «Уроки SQL» и составить общее представление о том, что к чему. Если хочешь порешать задачки и набить руку — для этого есть отдельные программы, например, «Интерактивный тренажер по SQL».
Вместо послесловия
Я надеюсь, что эта статья поможет тебе оценить путь, который нужно пройти для входа в Data Science, и принять финальное решение. В случае, если оно будет положительным, помни, что при должном упорстве всё получится! Кстати, недавно у нас вышла статья про основные инструменты дата-сайнтиста, необходимые в работе 🙂
В прошлой статье мы рассматривали неочевидные проблемы АБ тестирования и как можно с ними справляться. Но часто бывает так, что при внедрении новой функциональности АБ тестирование провести нельзя. Например, это типично для маркетинговых кампаний нацеленных на массовую аудиторию. В данной ситуации существует вероятность того, что пользователи контрольной группы, которым недоступна рекламируемая функциональность, начнут массово перерегистрироваться. Также возможен сценарий, при котором возникнет значительное количество негативных отзывов из-за воспринимаемой дискриминации. Но задача оценки таких нововведений одна из наиболее частых, которые приходится решать аналитикам. Если метрики только улучшаются, то это обычно легко объяснить хорошей работой, а если метрика ухудшилась, то сразу появляется задача на аналитика. В этой заметке мы рассмотрим первую часть задачи — а действительно ли метрика упала и если да, то имеет ли смысл разбираться дальше?
Важно определить, с чем проводить сравнение. Обычно выбирают предыдущий месяц, аналогичный календарный месяц предыдущего года или другую географическую область. Но в отсутствии хорошо спроектированного АБ теста достоверного на 100% сравнения не получится. Поэтому стоит выбирать то, что больше подходит под конкретную задачу.
Далее возникает вопрос, достаточно ли данных для применения хоть какой-то статистики? Если наблюдений всего 5-10, и они сильно зашумлены, то смысл в исследовании теряется. В этом случае чаще всего стоит остановиться с простым выводом — достоверно определить есть ли разница и почему – невозможно.
Посмотрим на типичный график, с которым приходиться работать аналитикам
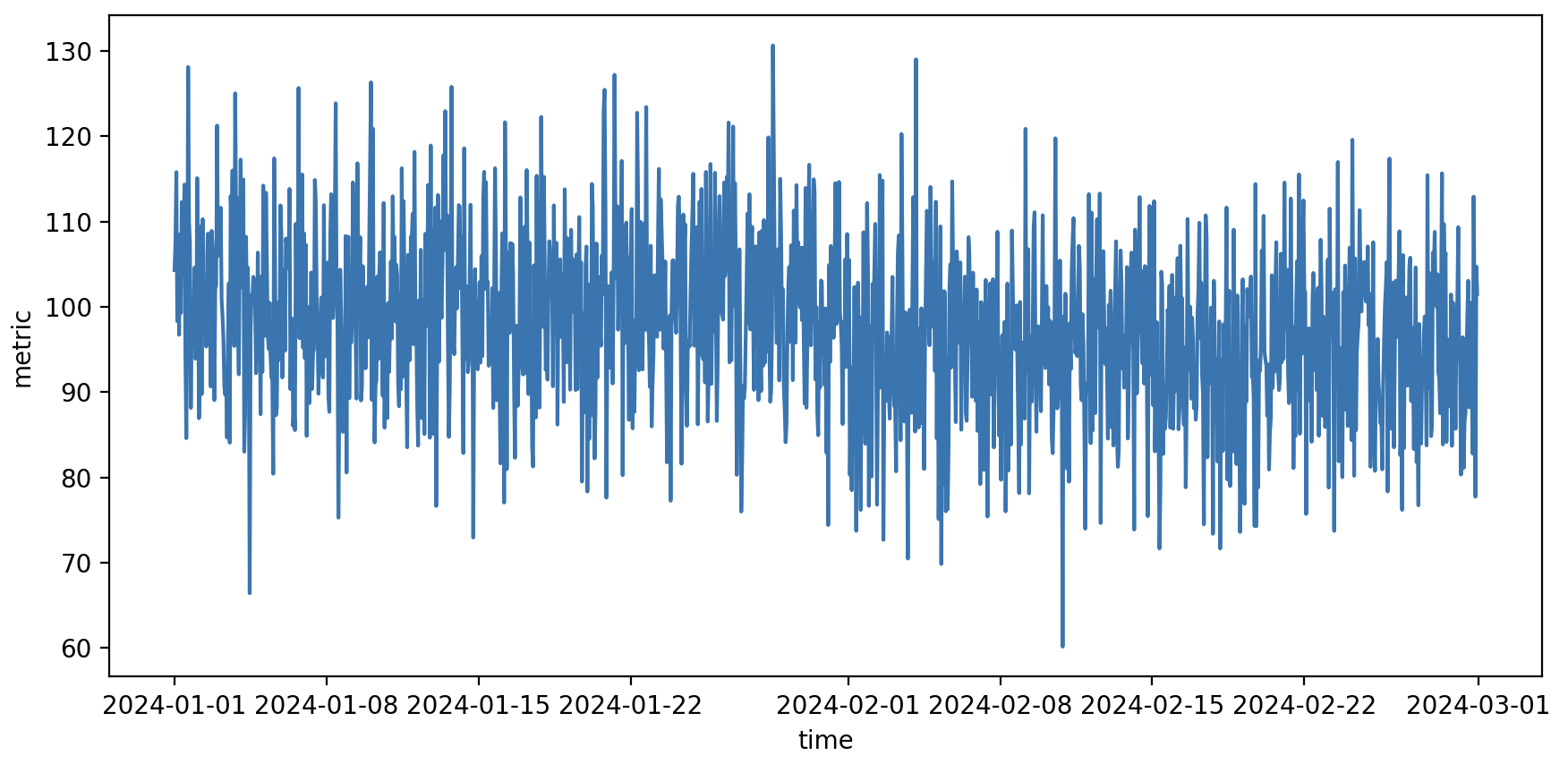
Синтетический пример шумной метрики metric за два месяца измерений.
Метрика шумная, что затрудняет визуальную оценку. При выборе двух точек данных до и после изменений можно наблюдать как увеличение, так и уменьшение значений, в зависимости от конкретных выбранных точек. Тем не менее, общее впечатление состоит в том, что среднее значение стало ниже. Как это проверить?
Простое сравнение средних
Первая идея — найти среднюю на пред периоде, среднюю на пост периоде и сравнить.
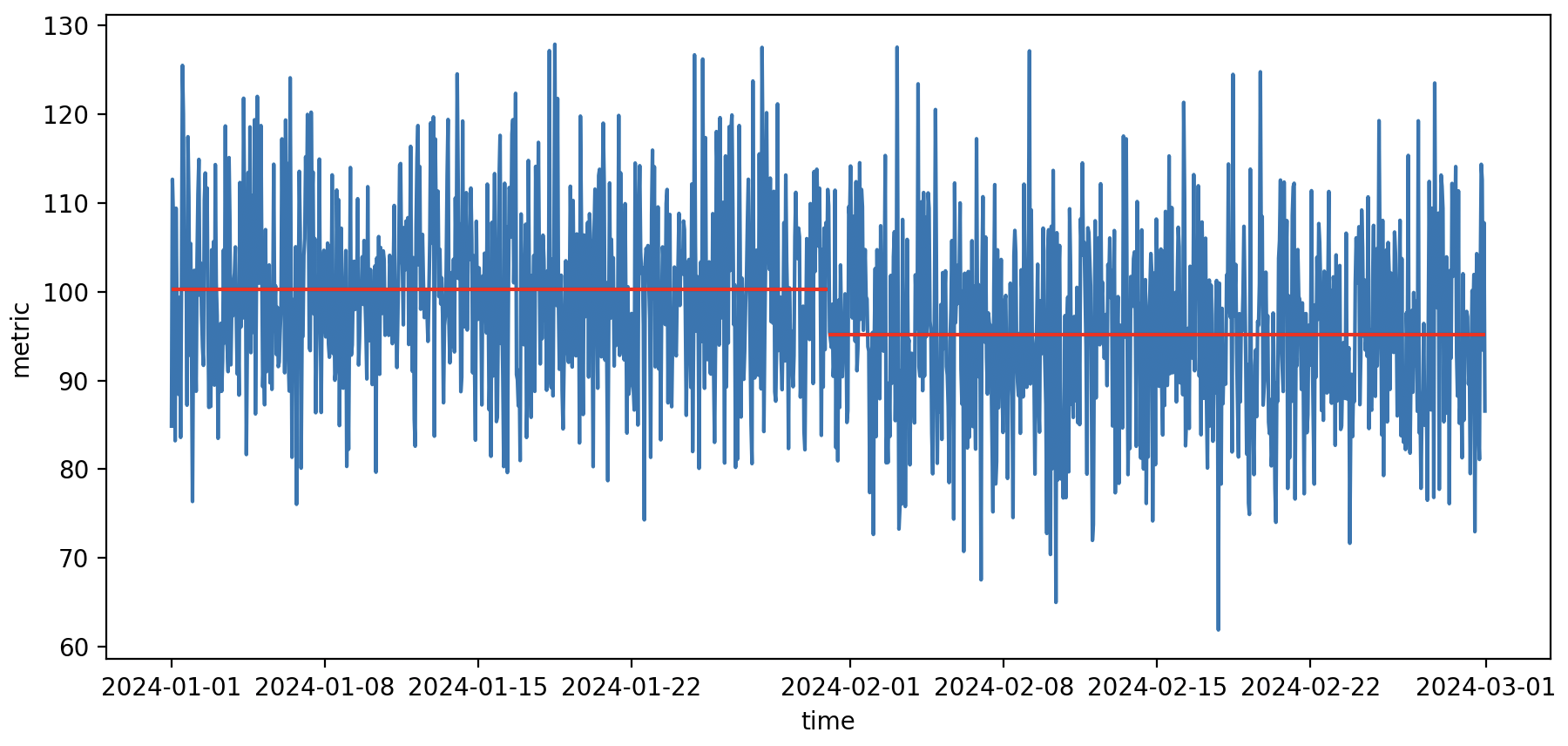
Сравнение метрики для двух соседних месяцев через сравнение средних
Даже при отсутствии реальной разницы между средними значениями, вероятность того, что два средних совпадут практически нулевая. В половине случаев правая средняя будет меньше, просто из-за случайных колебаний. Рассмотрим несколько возможных подходов для более объективного анализа.
Тест Стьюдента
t-тест, является одним из наиболее широко используемых и эффективных методов для сравнения средних значений. При его применении важно проверять условия, при которых ему можно доверять:
Проверить можно визуально, с помощью, например, QQ-plot, либо с помощью тестов на распределение (Шапиро-Вилка, Колмогорова-Смирнова, и других). Если одно из условий нарушено, то нужно применять другие методы
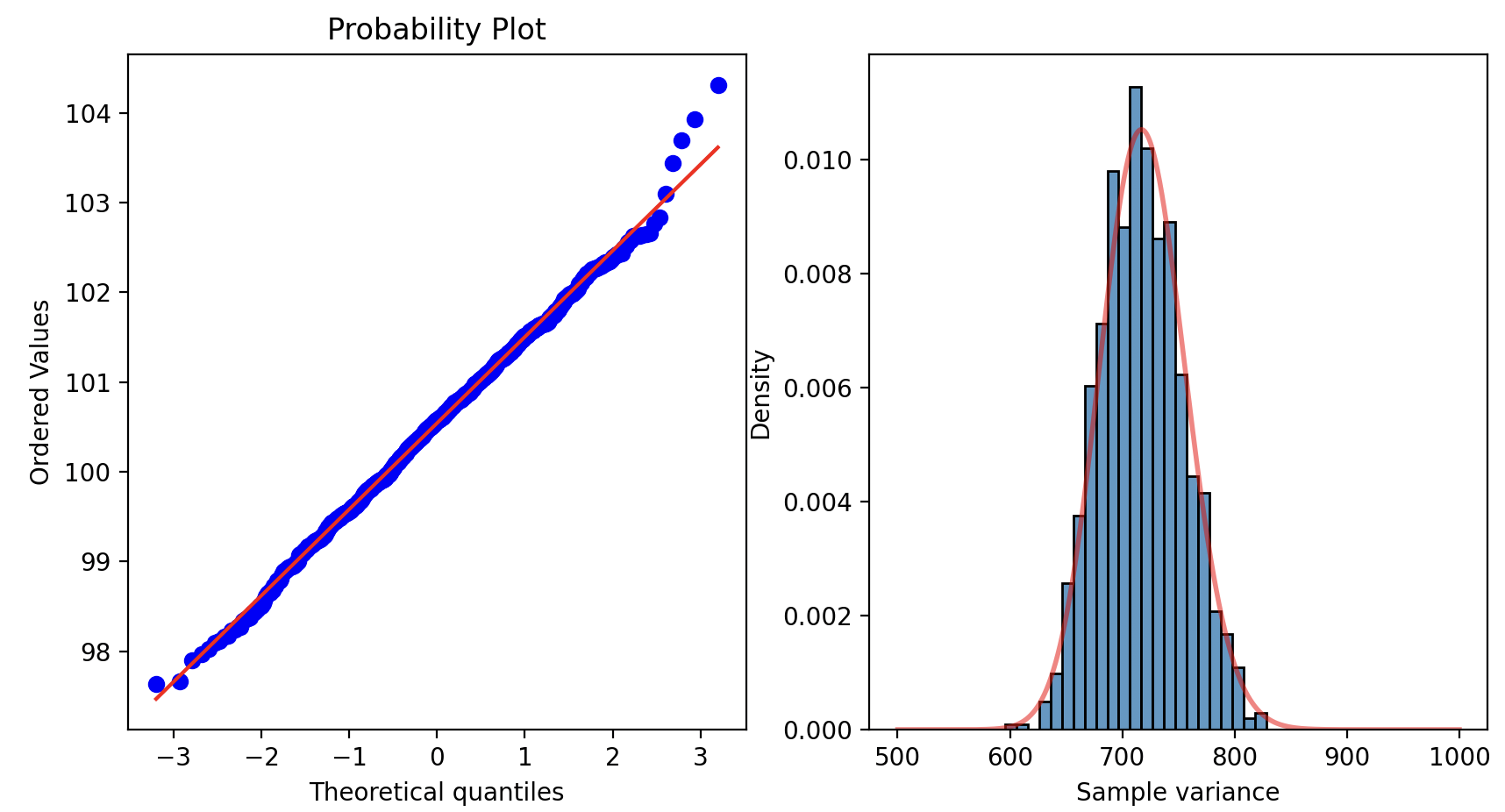
Визуальная проверка условий t-test
В рассмотренном случае различия статистически значимы.
Тест Манна-Уитни
Мана-Уитни, U-test. Этот тест не подходит для сравнения средних. Подробнее можно посмотреть в статье Ниже приведём пример моделирования 1000 тестов двух распределений с одинаковым средним и разными дисперсиями.
U-test систематически выдаёт большее количество ложных срабатываний (существенно больше чем в 5% случаев) чем t-test при одинаковом уровне alpha = 0.05. По похожим причинам не подходят тест Колмогорова-Смирнова и некоторые другие тесты, сравнивающие распределения случайных величин, вместо средних.
Бутстрап
Основная идея — генерировать 1000 новых датасетов из исходного случайным сэмплированием с повторениями и определить доверительный интервал через квантили. Применимость бутстрапа очень широка, это связано с тем, что он не требует нормальности распределения средних случайной величины. Бутстрап позволяет построить как доверительные интервалы для пост периода и предпериода в отдельности, так и интервал для разности средних. Если доверительный интервал разности средних не содержит 0, то разница статистически значима. Хорошее описание приведено в книге Efron B. Bootstrap confidence intervals for a class of parametric problems, Biometrika 1985.
Когда выборка содержит выбросы или неточности, бутстрап может обеспечить устойчивость при оценке параметров модели, так как этот метод создает множество подвыборок, в каждой из которых могут быть учтены различные комбинации данных, включая выбросы. Анализ статистик, полученных из этих подвыборок, может предоставить информацию о диапазонах возможных значений параметров и их доверительных интервалах.
Однако стоит отметить, что бутстрап не гарантирует полное устранение влияния выбросов или грязи в данных, а также плохо работает на маленьких выборках. В некоторых случаях выбросы могут сохраняться в различных подвыборках, и они могут по-прежнему влиять на оценки модели. Бутстрап предоставляет инструмент для более устойчивой оценки, но не является универсальным средством решения всех проблем с выбросами или неточностями в данных.
Тем не менее, важно, что если исходные данные содержат систематическую зависимость или нарушение независимости (например, временные зависимости), бутстрап может не учитывать этот аспект. В таких случаях более тщательные методы, специфичные для типа данных, могут потребоваться для учета зависимости между наблюдениями.

Доверительный интервал для постпериода: (94.03, 95.58)
Доверительный интервал для предпериода: (99.28, 100.73)
Доверительный интервал для разницы средних: (-6.19, -4.20). Различия статистически значимы.
Тест перестановок
В некотором смысле похож на бутстрап, но позволяет работать с выборками разного размера, хотя более вычислительно сложный. Если бутстрап на практике хорошо работает с 1000 итераций семплирования, то для теста перестановок нужно примерно 100000 итераций (подробнее описано в книге Bootstrap Methods And Permutation Tests Companion Chapter 18 To The Practice Of Business Statistics).
Тест перестановок основан на идее того, что при справедливости нулевой гипотезы распределение данных не изменится при случайных перестановках меток групп. Таким образом, сравнение наблюдаемого значения с распределением, полученным путем перестановок, позволяет делать выводы о статистической значимости различий между группами.
P-значение для перестановочного теста много меньше 0.05. Различие статистически значимо (alpha = 0.05).
Байесовский подход
Предположим, что метрика имеет известное распределение. Тогда можно по данным на предпериоде определить какое значение среднего является наиболее вероятным и какой у него доверительный интервал. Тоже самое можно проделать и для постпериода. Тогда сравнив два доверительных интервала можно сделать вывод о их различии. Альтернативно, можно посчитать вероятность увидеть данные постпериода, при фиксированных параметрах распределения на предпериоде. Такой подход может быть эффективным, если правильно угадать форму и тип распределения данных даже при очень не больших выборках.
Хороший пример и объяснение такого подхода можно найти на странице проекта pymc, а подробный разбор выходит далеко за рамки данной статьи. Далее в примере мы генерировали из нормального распределения, однако, на деле будет не лишним убедиться, что метрика и правда распределена нормально (или же иначе в зависимости от вашей гипотезы).


Доверительный интервал для предпериода: (99.48, 100.89)
Доверительный интервал для постпериода: (94.03, 95.50)
Интервалы не пересекаются, различие статистически значимо
Заключение
Мы рассмотрели несколько популярных подходов, но многие современные методы, связанные с машинным обучением, остались в стороне. Например подходы causal inference, Difference in Difference, и некоторые другие методы основанные на конструировании синтетического контроля можно найти например в статье Spotify, «Causal Inference in Statistics: A Primer» by Judea Pearl, «Counterfactuals and Causal Inference: Methods and Principles for Social Research» by Stephen L. Morgan and Christopher Winship, и других.
Опытный аналитик отметит, что если есть устойчивый нисходящий тренд, то при анализе стоит учитывать этот фактор, так как в таком случае на постпериоде мы всегда увидим занижение среднего. Часть указанных выше продвинутых методов позволяют учесть тренд, но для начала нужно определить, а есть ли тренд? В следующей статье мы обсудим подходы к определению тренда и их применимость на практике.
— Что работодатели хотят от джуниор аналитика данных?— Работодатели хотят, чтобы он был мидлом.
Если ты не смеёшься над этим анекдотом, то наверняка недавно закончил (либо заканчиваешь) обучение по обретению специальности «Аналитик данных». А ещё ты пока не нашел, но уже начал искать свою первую работу.
Меня зовут Ольга Матушевич, я наставник на курсе «Аналитик данных» в Практикуме. В этой статье я предложу решение проблемы «как получить опыт работы, если без опыта никуда не берут» с помощью самостоятельных проектов.
Сделают ли самостоятельные проекты меня мидлом
Самостоятельные проекты сделают тебя джуном плюс. Вот как ты изменишься при работе над внеучебными проектами.
В любом случае опыт работы с реальными данными на учебных курсах приобрести сложно. И работодатели это понимают.